Podczas komunikacji synchronicznej może nastąpić szereg problemów z połączeniem do innego systemu. Problem może szybko się samoistnie rozwiązać lub trwać dłuższą chwilę powodując awarię. W dalszej części artykułu rozważamy schemat synchronicznej komunikacji pomiędzy Serwisem A i B, tj. Serwis A składa żądanie do Serwisu B i czeka na odpowiedź wstrzymując pracę. W przypadku błędu komunikacji jest od razu zauważany i zgłaszany jako problem w Serwisie A.

Żądania mogą nie udać się (szybko)
Pewne problemy z połączeniem objawiają się szybko. Przykładem może być nierozwiązywalny host DNS, kiedy połączenie jest natychmiast przerywane. Podobnie jest gdy zostanie napotkany nieważny certyfikat SSL, połączenie jest przerywane.
Żądania trwają długo, aż do osiągnięcia timeoutu
Istnieją sytuacje, gdy przetwarzanie żądań trwa zbyt długo z powodu spadku przepustowości systemu. Usługa może być przeciążona lub czekać na inne zasoby. Można przyjąć pewien czas (timeout), po którym system wywołujący nie czeka już na odpowiedź, natomiast wszystkie żądania do serwisu przez dłuższy czas nie będą udawać się tak na prawdę z tego samego powodu i ponowna próba prawdopodobnie się nie powiedzie. Odpowiednio krótki timeout może okazać się zbyt krótki.
Efekt kuli śnieżnej
Efekt kuli śnieżnej (Snowball Effect) występuje, gdy Serwis A ma awarie z powodu wysycenia zasobów przez czekanie na Serwis B, ten przez Serwis C itd, itd. Dochodzi do sytuacji, że z powodu awarii jednego z serwisów zasięg awarii powiększa się o wszystkie komponenty komunikujące się z nim.
Efemeryczne środowiska
W dynamicznych środowiskach przyjmuje się efemeryczną żywotność pojedycznych instancji systemu, które są wykrywane dynamicznie (service discovery). Oznacza to, że z natury instancja usługi może przestać działać, zatem klient usługi powinien być przygotowany, że synchroniczne żądanie do niej mogą się nie powieść i należy obsłużyć taką sytuacją.
Circuit Breaker Pattern
Dla dłuższych niedostępności, aby nie doprowadzić do efektu kuli śniegowej i zwiększyć user experience warto rozważyć wzorca Circuit Breaker (Bezpiecznika). Zapobiega on powtarzaniu operacji, które prawdopodobnie się nie powiodą. Ideą jest rozpoznanie problemu, przełączenie się na scenariusz alternatywny (fallback) i nie eskalowanie tego problemu dalej.
Wzorzec ma swoją inspirację w tym z układów elektrycznych. Kod wywołujący zdalną usługę (potencjalnie awaryjny) umieszczamy za bezpiecznikiem.
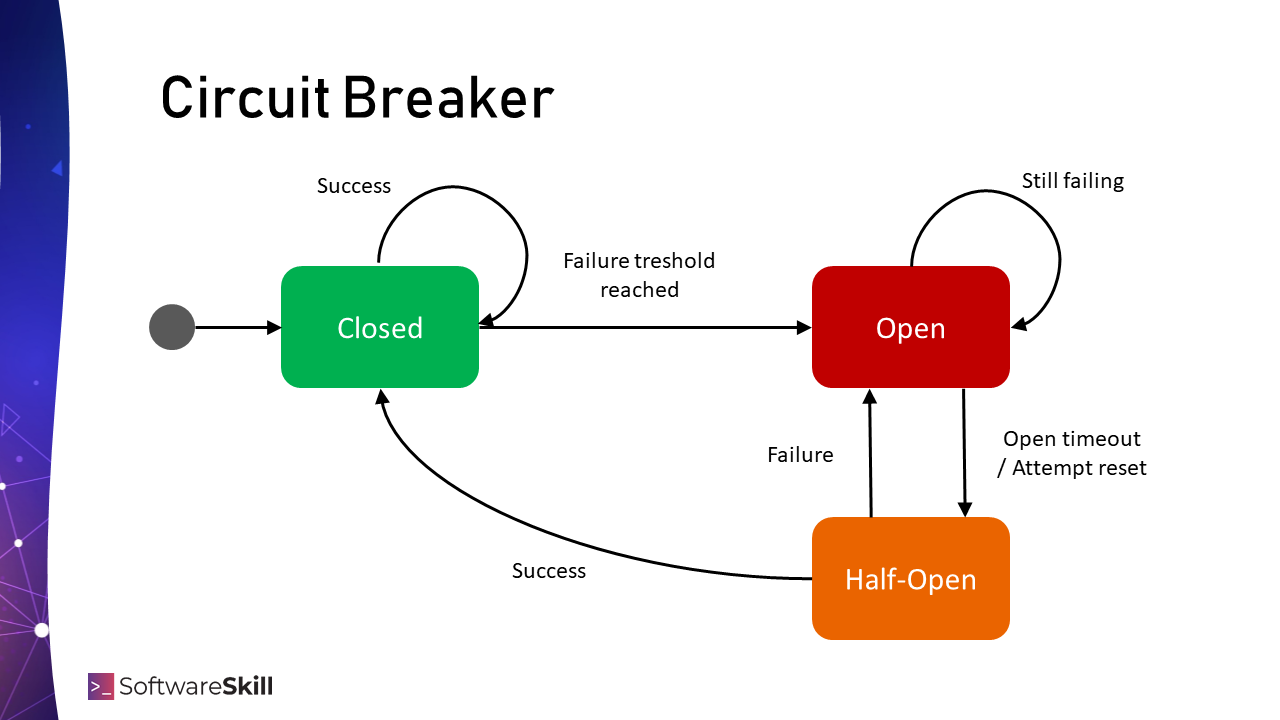
Bezpiecznik to prosta maszyna stanów z trzema stanami: ● Zwarty (closed), ● Rozwarty (open), ● Pół-rozwarty (half-open).
- Zwarty oznacza prawidłowy przepływ (tak jak zwarty układ elektryczny).
- Rozwarty to odcięty dostęp do kodu (odpowiednik rozwartego układu elektrycznego).
- Pół otwarty to stan przejściowy ze stanu rozwartego, gdy dokonywana jest ponowna próba wywołania kodu.
Podczas wywoływania kodu mierzony jest jego rezultat. Każdorazowe wywołanie:
- bez wyjątku liczone jest jako sukces,
- zakończenie kodu wyjątkiem to błąd.
Maszyna stanów rozpoczyna swoje działanie w stanie Closed, zakładając że funkcjonalność za bezpiecznikiem działa. Statystyka jest zliczana w wybranej metryce, dajmy na to liczba błędów w jednostce czasu. Jeżeli funkcjonalność przestaje działać i przekracza pewien ustalony poziom, wtedy bezpiecznik zmienia stan do Open i zakłada scenariusz alternatywny (fallback). Dalsze wywołania próby kodu za bezpiecznikiem nie wywołują go, tylko zwracają ustalony wcześniej wynik. Co jakiś ustalony czas bezpiecznik wchodzi w stan Half-Open, w którym ponawiana jest próba wywołania kodu, aby upewnić się, czy sytuacja uległa poprawie. Tutaj są dwie możliwości: jeżeli kod zaczyna działać, stan jest zmieniany do Closed, a przeciwnym wypadku z powrotem do Open.
Stan Open i Half-Open są kluczowe w zasadzie działania wzorca bezpiecznika. To właśnie ta część powoduje, że problem się nie nasila – jeżeli wiele wywołań z rzędu osiągnęło jakiś poziom błędu, oznacza to, że kolejne prawdopodobnie też się nie powiodą i problem nie jest eskalowany, a zamiast tego przyjmowana jest akcja fallback, która natychmiastowo zwraca jakiś ustalony wynik.
Innymi słowy, system zostaje zaprojektowany zgodnie z zasadą „safe to fail”, czyli bezpiecznie w razie uszkodzenia.
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
Implementacja: biblioteka resilience4j
Circuit Breaker pattern jest zaimplementowany m.in. w bibliotece resilience4j:
- to lekka, łatwa do użycia biblioteka Java
- stworzona pod Java 8 i wywołania lambd
- wspiera paradygmat programowania funkcyjnego dekorując funkcje
- implementuje wzorce: Circuit Breaker, Rate Limiter, Retry, Bulkhead
- gotowa integracja eksporu statystyk do micrometer.
Przykład użycia:
CircuitBreaker circuitBreaker = CircuitBreaker.ofDefaults("name");
Supplier<String> supplier = () -> service.sayHelloWorld(param1);
String result = Decorators.ofSupplier(supplier)
.withCircuitBreaker(CircuitBreaker.ofDefaults("name"))
.withFallback(asList(CallNotPermittedException.class, BulkheadFullException.class),
throwable -> "Hello from fallback")
.get()
lub metoda zgłaszająca wyjątek wykorzytując Checked Supplier i Try:
CircuitBreaker circuitBreaker = CircuitBreaker.ofDefaults("name");
Try<String> result = Try.of(CircuitBreaker.decorateCheckedSupplier(circuitBreaker, () -> service.sayHelloWorld(param1)))
.recover(throwable -> "Hello from fallback");
Co musisz skonfigurować
W powyższych przykładach używałem skonfigurowanego domyślnie circuitBreaker.
Aby świaodmie użyć bezpiecznika, należy skonfigurtować:
- Jak mierzone są błędy – treshold – czyli stosunek udanych prób do nieudanych:
- count-based sliding window – zlicza n ostatnich wywołań, nie zwracając uwagi na przedział czasowy
- time-based sliding window – zlicza wywołania w wybranym przedziale czasowym T, nie ważne ile ich było
- failure rate treshold – przy jakim stosunku udanych i nieudanych prób uaktywnić bezpiecznik
- slow rate treshold – jaki jest akceptowalny poziom operacji, które są „wolne”, trwają dłużej niż określony czas – są one interpetowane jak błędy
- number of calls permitted in half-open state – liczba dopuszczalnych prób testowanych wywołań w stanie Half-Open, które zdeterminują powrót do stanu Closed lub Open.
Koniugując powyższe parametry masz pełną kontrolę nad systemem. Ich doboru można dokonać empirycznie.
Jaki fallback przyjąć?
Zakładając komunikację synchroniczną, od razu powinieneś zastanowić się, co ma się zdarzyć w scenariuszu alternatywnym, gdy operacja się nie powiedzie. Warto o tym porozmawiać z biznesem.
Kilka heurystyk, które można przyjąć:
- Zaplanować ponowienie operacji za jakiś czas.
- Jeżeli nie jest to krytyczna funkcjoanlność – ominąć kawałek procesu/sprawdzeń, przepuścić cały proces dalej i zaalarmować w monitoringu.
- Jeżeli to krytyczna funkcjonalność lub rośnie ryzyko z ominięciem kroku w procesie – zatrzymać proces.
- Powiedzieć klientowi: „tym razem trwa to dłużej niż zwykle, damy znać”.
- Manualna kompensacja problemu (w backoffice).
Wszystko zależy od przypadku użycia i priorytetów, którymi kieruje się biznes. Czasem stratą wizerunkową może być np. ominięcie części procesu (np. sprawdzeń) i lepiej pozytywnie klientowi pozwolić na coś, a innym razem może ryzyko z działaniem procesu dalej jest zbyt duże i lepiej poinformować klienta, że na ten moment system nie udzieli odpowiedzi.
Na co jeszcze zwrócić uwagę
- Jeżeli stosujesz client-side load balancing (proces odpytuje instancje, a nie działa przez proxy i load-balancer) – pamiętaj, aby za bezpiecznikiem chować wywołania poszczególnych instancji serwisu, a nie całego serwisu. Możesz bowiem doprowadzić do sytuacji, że w przypadku niedziałającej części instancji funkcjonalność zostanie całkowicie wyłączona mimo redundancji, którą posiadasz.
- Circuit Breaker pattern możesz stosować razem z mechanizmem Retry, aby ponowić operację przynajmniej jeden raz. Szczególnie ważne jest to w przypadku client-side load balancing, gdy zlecasz operację danym instancjom – wtedy spróbuj odpytać do momentu, kiedy odpytasz wszystkie, które są nieawaryjne.
- Skonfiguruj bezpiecznik dobrze gwarantując powrót do stanu Closed, w przeciwnym wypadku maszyna stanów nigdy już nie powróci do poprawnego scenariusza.
- Skonsultuj alternatywny scenariusz z biznesem.
Inne typy Circuit Breaker
- Distributed Circuit Breaker – bezpiecznik z rozproszonym stanem. Wszystkie instancje Twojego serwisu globalnie znają stan serwisu, z którym się komunikują. W zwykłym bezpieczniku, każda instancja „musi się zorientować” samodzielnie.
- Service Mesh – rozwiązania z wbudowanym bezpiecznikiem i logiką poza kodem aplikacji (bibliotekami).
- Konfigurowalna warstwa infrastruktury w skonteneryzowanym świecie.
- Jako sidecar container, który zapewnia auto-discovery, auto-healing.
- Przykład: istio.io.
Wpis który czytasz to zaledwie fragment wiedzy zawartej w Programie szkoleniowym Java Developera od SoftwareSkill. Mamy do przekazania sporo usystematyzowanej wiedzy z zakresu kluczowych kompetencji i umiejętności Java Developera. Program składa się z kilku modułów w cotygodniowych dawkach wiedzy w formie video.
Literatura
- https://martinfowler.com/bliki/CircuitBreaker.html
- https://resilience4j.readme.io/docs/circuitbreaker
- https://www.nginx.com/blog/what-is-a-service-mesh/
- https://istio.io/
Podoba Ci się ten artykuł? Weź więcej.
Jeżeli uważasz ten materiał za wartościowy i chcesz więcej treści tego typu – nie przegap ich i otrzymuj je prosto na swoją skrzynkę. Nawiążmy kontakt.
Gdybyś potrzebował jeszcze więcej:
Jesteś Java Developerem?
Przejdź na wyższy poziom wiedzy
„Droga do Seniora” 🔥💪
Jesteś Team Leaderem? Masz zespół?
Podnieś efektywność i wiedzę swojego zespołu 👌
Obraz: Dom zdjęcie utworzone przez pvproductions – pl.freepik.com
