Code Coverage to metryka jakościowa, która określa, w jakim stopniu kod produkcyjny jest uruchamiany podczas wykonywania zestawu testów. Program o wyższym Code Coverage, wyrażanym w procentach, z założenia jest uruchamiany w większym zakresie, przez co można wnioskować, że skoro testy się powiodły, program zawiera mniej błędów.
Z tego artykułu dowiesz się
- W jaki sposób mierzony jest Code Coverage.
- Czy zielone testy i 100% Code Coverage pozwala na Continuous Delivery na produkcję.
- Jakich 3 pułapek należy się ustrzec.
- 5 sposobów Jak mądrze wykorzystać Code Coverage.
- Jak skonfigurować wyznaczanie metryki Code Coverage.
Piguła wiedzy o najlepszych praktykach testowania w Java
Pobierz za darmo książkę 100 stron o technikach testowania w Java

Jak mierzony jest Code Coverage?
Na wstępie warto zaznaczyć, w jaki sposób mierzony jest Code Coverage. Celem jest sprawdzenie, jako fragment kodu produkcyjnego został „pokryty testami”, czyli uruchomiony podczas ich wykonywania. Należy to jakoś skwantyfikować. Istnieje kilka zasadniczych metryk. Wyszczególnię je od najbardziej ogólnych do szczegółowych:
- Class/Methods coverage wskazuje jaki procent klas/metod został wywołany w zestawie testów.
- Branches coverage mówi o tym, ile całych gałęzi kodu (wariantów if/else, instrukcji switch-case) zostało wykonanych.
- Condition Coverage sprawdza, czy każdy pojedynczy warunek został spełniony i niespełniony. Jeżeli dana gałąź kodu oparta jest na warunku
A && B, sprawdzane jest spełnienie i niespełnienie osobnoAiB. - Line Coverage oznacza, ile linii kodu programu zostało uruchomionych. Jest to najczęściej raportowana metryka.
Technicznie podczas wykonywania kodu produkcyjnego uruchamianego przez testy potrzebna jest tzw. instrumentacja kodu, czyli jego modyfikacja. Do kodu dodawane są markery zliczające metryki. Podczas zliczania Code Coverage rozwiązania typu JaCoCo, IntelliJ Coverage zapewniają uruchomienie kodu z agentami przeprowadzającymi instrumentację.
Czy 100% Code Coverage oznacza brak błędów?
Mogłoby się wydawać, że 100% Code Coverage to święty graal do dostarczania stabilnych rozwiązań. W rzeczywistości metryka podatna jest na następujące sytuacje:
1. Niewystarczająco dokładne asercje
To, jak wiele linii kodu zostaje wykonanych, może być nieistotne w obliczu niewystarczających asercji. Bo co oznacza wykonanie całego przebiegu programu bez sprawdzenia, czy wystarczająco dobrze się wykonał? Aby bardziej to zobrazować: w skrajnym przypadku można dopuścić do sytuacji 100% Code Coverage przy braku jakichkolwiek asercji.
Jak przekonać się, czy aplikacja jest sprawdzana w wystarczającym wymiarze? Ciężko o dokładną odpowiedź. Przychodzi mi do głowy kilka propozycji:
- Proces Code Review – zespół na bieżąco opiniuje kod i sprawdza, czy wszystkie istotne przepływy oraz wyniki są sprawdzone wystarczająco dobrze.
- Testy mutacyjne – wprowadzanie intencjonalnych, drobnych zmian w kodzie (negacja/odwrócenie warunku, zmiana znaku liczby, itd.) i sprawdzenie, czy testy są nadal zielone. Jeżeli tak – testy nie sprawdzają kodu wystarczająco dobrze. Wadą tego typu testów jest ich wolne wykonywanie.
- Testy konwerterów – jeżeli to możliwe, w tym miejscu stosowanie Matek Obiektów i Test Builderów opartych o wspólne dane wartości konwertowanych i przyrównywanie całych obiektów zamiast asercje pole po polu, aby uniknąć niepokrytych nowych pól w przyszłości.
2. Zbyt duża izolacja i brak stosowania Piramidy Testów
Nadmierna ilość Testów jednostkowych przy braku Testów komponentowych może oznaczać, że testujemy jednostki w izolacji skonfigurowane zupełnie inaczej niż w aplikacji na produkcji. W takim przypadku okaże się, że mamy zielone testy i zepsutą produkcję.
Podobna sytuacja ma miejsce, gdy mamy nieodpowiednią proporcję Piramidy Testów – chodzi o brak testów komponentowych. Testy jednostkowe (na poziomie klas/pakietów i publicznego API) oparte wyłącznie o mocki i weryfikację interakcji (pobranie wartości lub wywołanie metody z odpowiednimi argumentami) mogą nie ujawnić błędów powstałych po integracji poszczególnych klas i pakietów tworzących całe funkcjonalności. Może okazać się, że założone wartości w rzeczywistości nigdy nie są zwracane, albo wywołanie metod powoduje błędy (nieotwarta transakcja, niezłapane wyjątki).
Dlatego warto jest mieć odpowiednią ilość testów komponentowych, aby złożyć ze sobą puzzle dokładnie tak samo, jak na produkcji i sprawdzić funkcjonalność jako całość.
Więcej o piramidzie testów i testach komponentowych przeczytasz tutaj.
3. Inna konfiguracja w testach, inna na produkcji
Tyczy się to głównie testów komponentowych. Jeżeli konfiguracja klas w testach będzie inna niż na produkcji – testy nie mają większego sensu. Możemy skończyć ze 100% Code Coverage i zepsutą produkcją.
Ja stosuję zasadę, że na poziomie testów komponentowych używam dokładnie takiej samej konfiguracji, jak produkcyjna (te same pliki @Configuration), a zamienione są tylko implementacje I/O (na implementacje in-memory, np. w przypadku bazy danych H2SQL lub proste implementacje in-memory, statyczne odpowiedzi z zależnych serwisów, które można zmieniać z poziomu testów w zależności od scenariusza).
O statycznych odpowiedziach z serwisów przeczytasz w artykule o Consumer-Driven Contract.
Jak mądrze wykorzystać Code Coverage?
1. False-Positive 100% Code Coverage
Po pierwsze, nie stosuj zasady 100% Code Coverage = pewność, że kod jest bezpieczny. Zwracaj szczególną uwagę na to, co jest sprawdzane przez testy podczas Code Review. O wadach metryki już wspomniałem, wystrzegaj się potencjalnych błędów.
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
2. Sprawdź raport dla krytycznych części kodu
Jeżeli jakiś fragment kodu jest bardzo krytyczny, przejrzyj raport Code Coverage. Może okazać się, że jeszcze nie pokryto wszystkich przypadków – warto to zrobić.
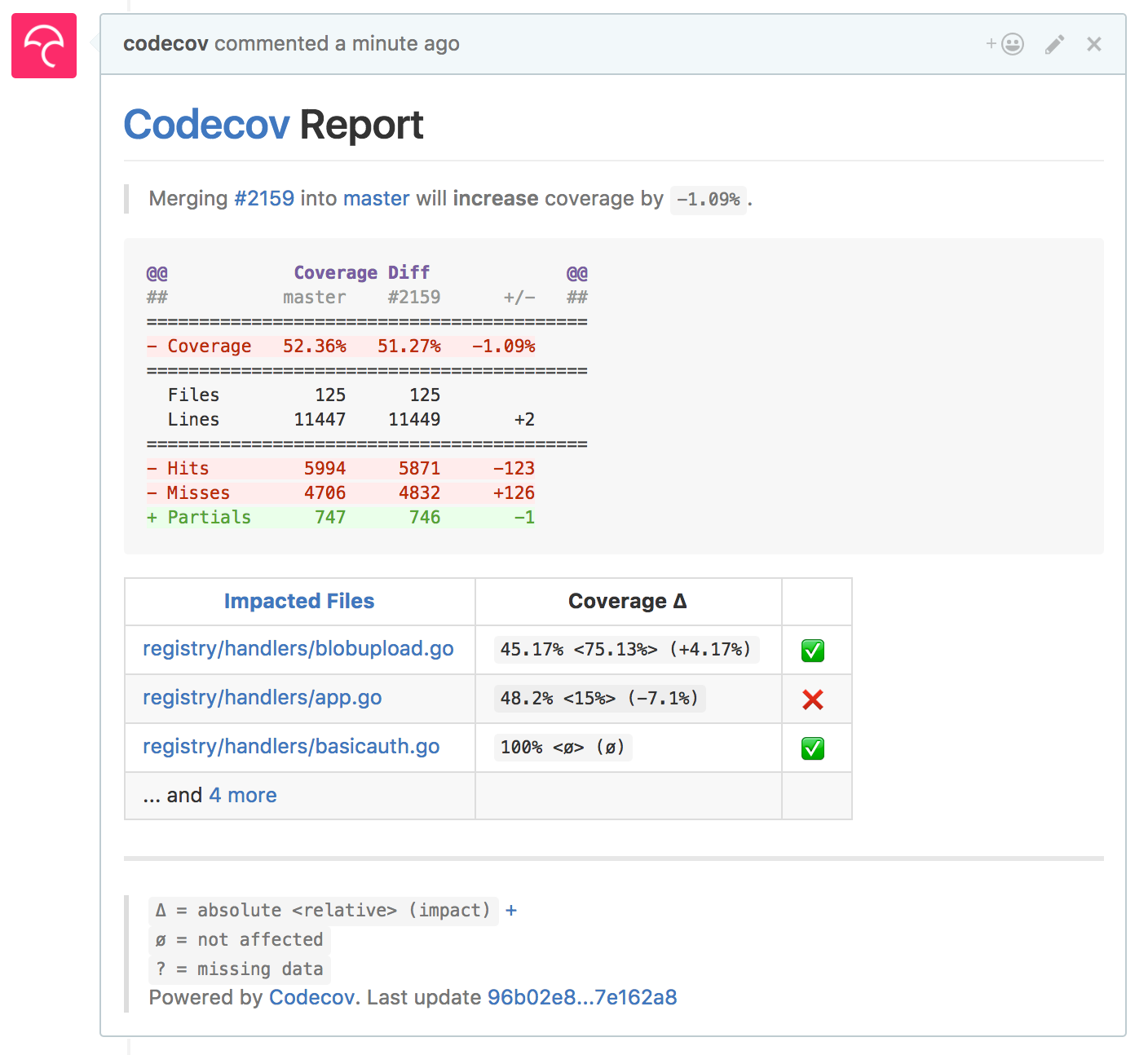
3. Zwracaj uwagę na Delta Coverage
Delta Coverage to różnica w metryce Code Coverage pomiędzy zmianami. Jeżeli metryka jest na poziomie 86% na głównej gałęzi, a po Twoich zmianach metryka spada do 82%, oznacza to, że wprowadzono kod, który jest przetestowany w mniejszym stopniu, niż był przetestowany do tej pory. To sygnał do poprawy.
4. Wykluczaj kod z metryki Code Coverage
Po drugie, jeżeli przeglądasz raport i pewne klasy nie są pokryte i obniżają Code Coverage (np. klasy konfiguracji Spring, implementacje in-memory) – wyklucz je z raportu. Te fragmenty nie są używane na produkcji. Jeżeli masz wystarczająco dobre testy komponentowe, masz wystarczająco dużą pewność, że kod jest pokryty.
5. Podnieś Code Coverage – usuwaj martwy kod
Najlepszym sposobem na podniesienie Code Coverage jest wyrzucenie martwego (nieużywanego) kodu, który na dodatek nie jest dobrze przetestowany. Kod częściej się czyta, niż pisze. Wyrzucenie kodu nie oznacza, że go stracisz na zawsze – będzie on nadal w historii repozytorium. Lepiej go przywrócić, niż przypadkowo wykorzystać.
Konfiguracja Code Coverage w Java
Istnieje wiele metod liczenia Code Coverage w Java. Osobiście używam projektu JaCoCo, ponieważ:
- Sam z siebie generuje dobre raporty
- Integruje się z rozwiązaniami typu:
Do pliku pom.xml doklej następujący fragment:
<build>
<plugins>
<plugin>
<groupId>org.jacoco</groupId>
<artifactId>jacoco-maven-plugin</artifactId>
<version>0.8.5</version>
<executions>
<execution>
<id>default-prepare-agent</id>
<goals>
<goal>prepare-agent</goal>
</goals>
</execution>
<execution>
<id>default-report</id>
<goals>
<goal>report</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
Dodatkowo ja stosuję wykluczenia, nie wliczam w metryki plików konfiguracyjnych spring’a oraz swoich implementacji in-memory:
[...]
<execution>
<id>default-report</id>
<goals>
<goal>report</goal>
</goals>
<configuration>
<excludes>
<!-- ignore config classes -->
<exclude>**/*Config.*</exclude>
<!-- ignore in-memory impl -->
<exclude>**/inmemory/**</exclude>
</excludes>
</configuration>
</execution>
[...]
Przykładowy raport:


Zakończenie
Metryka Code Coverage może być dobrą wskazówką do niepokrytych fragmentów kodu. Możemy wykorzystywać Delta Coverage pomiędzy zmianami, aby zidentyfikować braki w testowanych fragmentach kodu i nie doprowadzać do pogarszania metryki.
100% Code Coverage nie zapewnia braku błędów ze względu na to, że nie sprawdza jakości uruchamianych testów (poprawnych asercji) oraz finalnej konfiguracji aplikacji.
Wpis który czytasz to zaledwie fragment wiedzy zawartej w Programie szkoleniowym Java Developera od SoftwareSkill. Mamy do przekazania sporo usystematyzowanej wiedzy z zakresu kluczowych kompetencji i umiejętności Java Developera. Program składa się z kilku modułów w cotygodniowych dawkach wiedzy w formie video.
Piguła wiedzy o najlepszych praktykach testowania w Java
Pobierz za darmo książkę 100 stron o technikach testowania w Java
Podoba Ci się ten artykuł? Weź więcej.
Jeżeli uważasz ten materiał za wartościowy i chcesz więcej treści tego typu – nie przegap ich i otrzymuj je prosto na swoją skrzynkę. Nawiążmy kontakt.
Gdybyś potrzebował jeszcze więcej:
Jesteś Java Developerem?
Przejdź na wyższy poziom wiedzy
„Droga do Seniora” 🔥💪
Jesteś Team Leaderem? Masz zespół?
Podnieś efektywność i wiedzę swojego zespołu 👌
Podsumowanie
Code Coverage to metryka jakościowa, która określa, w jakim stopniu kod produkcyjny jest uruchamiany podczas wykonywania zestawu testów. Program o wyższym Code Coverage, wyrażanym w procentach, z założenia jest uruchamiany w większym zakresie, przez co można wnioskować, że skoro testy się powiodły, program zawiera mniej błędów.
Istnieje kilka poziomów metryki Code Coverage:
Class/Methods coverage wskazuje jaki procent klas/metod został wywołany w zestawie testów
Branches coverage mówi o tym, ile całych gałęzi kodu (wariantów if/else, instrukcji switch-case) zostało wykonanych
Condition Coverage sprawdza, czy każdy pojedynczy warunek został spełniony i niespełniony. Jeżeli na dana gałąź kodu oparta jest na warunku A && B, sprawdzane jest spełnienie i niespełnienie osobno A i B.
Line Coverage oznacza, ile linii kodu programu zostało uruchomionych. Jest to najczęściej raportowana metryka.
Nie. Metryka Code Coverage może być dobrą wskazówką do niepokrytych fragmentów kodu. 100% Code Coverage nie zapewnia braku błędów ze względu na to, że nie sprawdza jakości uruchamianych testów (poprawnych asercji) oraz finalnej konfiguracji aplikacji.
Obraz: Technologia plik wektorowy utworzone przez stories – pl.freepik.com
