Z tego artykułu dowiesz się
Jeżeli interesują Cię tematy dotyczące organizacji logów takie jak:
- Praktyczne konfigurowanie biblioteki logowania na przykładzie Logback
- Traceability w logach
- Utrzymywanie plików logów
- Performance w logowaniu
- Logowanie w środowisku rozproszonym
Przed przeczytaniem tego artykułu musisz wiedzieć:
- Co umieścić w logach, aby były pożyteczne
- Jakie są poziomy logowania i jak je włączać
- Czym jest Slf4j
O czym przeczytasz w artykule: Logowanie aplikacji Java: Co, Kiedy, Gdzie i Jak?.
Tracebility
Solidnie obciążona aplikacja może produkować wiele logów. Ciężko jest przeglądać pliki logów, w których przeplatają się różne requesty czy wątki. Aby zachować pewną ciągłość operacji, warto skorzystać z jakiegoś elementu, który skoreluje nam logi powiązane ze sobą.
Na poziomie jednej aplikacji można przyjąć podejście, że dla każdego Requesta generujemy unikalny identyfikator i umieszczamy go w każdej linijce logu.
W tym celu korzystamy z MDC, czyli Mapped Diagnostic Context:
MDC.put("contextId", "some value...");
// ...
MDC.remove("contextId");
A w konfiguracji loga (Logback) używamy konstrukcji %X{contextId}:
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%date{"yyyy-MM-dd HH:mm:ss,SSSXXX", UTC} {%X{contextId}} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
Generowanie contextId na wejściu żądania HTTP uzyskamy w poniżej przedstawiony sposób. Dodatkowo do klienta zwracamy nagłówek z id requesta, po którym mógłby on zapytać nas o zdiagnozowanie sytuacji.
import org.slf4j.MDC;
import org.springframework.web.filter.OncePerRequestFilter;
import javax.servlet.FilterChain;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.util.UUID;
public class MdcFilter extends OncePerRequestFilter {
private static final String CONTEXT_ID_KEY = "contextId";
private static final String CONTEXT_ID_HEADER_NAME = "Request-Id";
@Override
protected void doFilterInternal(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, FilterChain filterChain) throws ServletException, IOException {
String requestId = generateRequestId();
MDC.put(CONTEXT_ID_KEY, requestId);
filterChain.doFilter(httpServletRequest, httpServletResponse);
MDC.remove(CONTEXT_ID_KEY);
httpServletResponse.addHeader(CONTEXT_ID_HEADER_NAME, requestId);
}
private static String generateRequestId() {
return UUID.randomUUID().toString();
}
}
Konfiguracja:
public class RestConfig {
@Bean
@Order(HIGHEST_PRECEDENCE)
MdcFilter mdcFilter() {
return new MdcFilter();
}
// ...
Kontekst jest trzymany dla wątku zatem jeżeli dojdzie do jego przełączenia, wszystkie informacje diagnostyczne przepadają, zatem przy zmianie wątku należy je zachować i przekazać do kolejnego wątku. Można stworzyć klasę dekorującą Runnable (kod poniżej), lub jeżeli używasz innych bibliotek od wykonywania kodu w sposób asynchroniczny, lub reaktywny typu RxJava, Project Reactor, konstrukcje te będą inne. Dla popularnych rozwiązań wystarczy jednak:
public static Runnable wrapMdc(final Runnable runnable) {
Map callingMdc = MDC.getCopyOfContextMap();
return () -> {
try {
MDC.setContextMap(callingMdc);
runnable.run();
} finally {
MDC.clear();
}
};
}
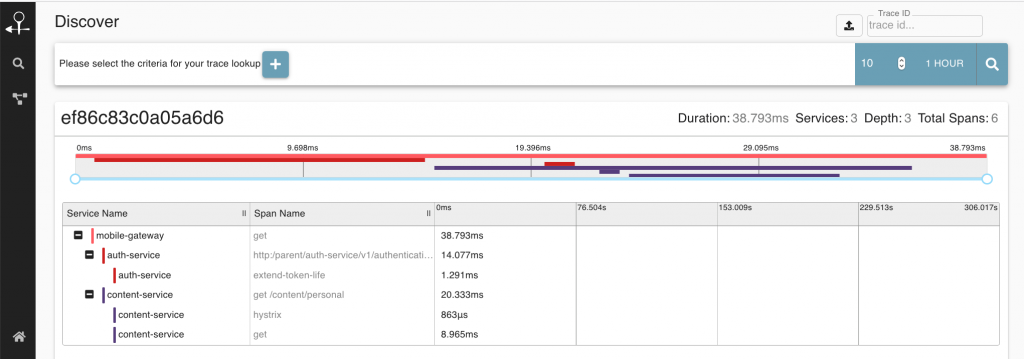
Powyżej zaimplementowana funkcjonalność śledzenia requesta w projekcie OpenTracing i podobnych nazywa się Trace (ścieżką). Jeden trace może uruchamiać kolejne, tworząc strukturę drabinki mierząc poszczególne operacje mające miejsce podczas wykonywania requesta.
Traceability w środowisku mikrousług
Problem skaluje się gdy w grę wchodzi kilka systemów. Do tej pory skupiliśmy się na tracebility requestu na poziomie pojedynczej aplikacji. Jeżeli natomiast żądanie przechodzi przez wiele systemów, warto na samym początku nadać globalny identyfikator SpanId i propagować je w systemie (np. za pomocą nagłówków HTTP w Requeście, nagłówku JMS/Messaging). Ogólna strategia może być taka:
- Jeżeli w nagłówku żądania nie występuje SpanId, to wygeneruj nowe.
- Jeżeli występuje, przyjmij je.
- Wysyłaj SpanId w każdym requeście.
Nakreślam tu tylko ideę z punktu widzenia logowania, aby taka informacja również znalazła się w logach, wtedy będziemy mogli wyekstrahować wszystkie logi związane z przetwarzaniem danego żądania od systemu początkowego, przez wszystkie wgłąb.
Problem tracingu rozwiązują projekty takie jak OpenTracing, Spring Cloud Sleuth, Zipkin i zachęcam się do zapoznania się z nimi.
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
Organizacja plików
Produkując pliki logów, z mojego doświadczenia wiem, że ważne jest kilka kwestii:
- Gdzie umieszczone są pliki
Warto, aby było to konfigurowalne (domyślna lokalizacja + możliwość nadpiania) - Podzielenie logów ze względu na datę
Łatwo wtedy odszukać interesujący nas fragment, błędy i incydenty można zawężać do ram czasowych - Pliki nie są większe niż zadany rozmiar
Nawet pliki logów są podzielone po dniach, mogą one przybierać większych rozmiarów, co czyni je ciężkimi nawet dogrepowania. Zadajmy im maksymalny rozmiar (np. 1GB)
Poniżej przykładowa konfiguracja produkcyjna logback-prod.xml, Aplikację uruchamiamy z parametrem wskazującym na plik, np. -Dlogging.config=/path/to/logback-prod.xml
<configuration>
<jmxConfigurator />
<property name="logfile" value="basket-service.log" />
<appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${logfile}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>${logfile}.%d{yyyy-MM-dd}.%i</fileNamePattern>
<maxFileSize>1GB</maxFileSize>
<maxHistory>10</maxHistory>
</rollingPolicy>
<encoder>
<pattern>%date{"yyyy-MM-dd HH:mm:ss,SSSXXX", UTC} {%X{contextId}} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<root level="info">
<appender-ref ref="file" />
</root>
</configuration>
Uwaga: Jeżeli aplikacja jest uruchamiana w kontenerze Docker, te zasady nie mają raczej zastosowania, ponieważ kontenery powinny logować do STDOUT i STDERR.
Usuwanie starych plików
Dobrze jest też zipować pliki starsze np. niż X_DNI i usuwać stare pliki – starsze niż Y_DNI dni. Można to zrobić za pomocą usługi systemowej linuxa Logrotate, albo np. cronem:
# usun stare i niepotrzebne pliki logow sprzed X_DNI
0 1 * * * find /some/path/to/dir -type f -mtime +X_DNI -exec rm {} ; > /dev/null 2>&1
# zgzipuj starsze pliki logow niz Y_DNI
0 1 * * * find /some/path/to/dir -type f -mtime +Y_DNI -exec gzip {} ; > /dev/null 2>&1
Performance
Logowanie co do zasady nie powinno zbyt mocno obciążać aplikacji. Należy uświadomić sobie dwie zasadnicze rzeczy:
- Gdy podajemy parametr do logowania, wykonywana jest na nim metoda
toString(), ale tylko wtedy, kiedy dany poziom logowania jest włączony. Zbędne jest pisanie poniższego kodu, ponieważ argumenty wypisane zostaną dopiero wtedy, gdy poziom DEBUG jest włączony:
if (logger.isDebugEnabled()) {
logger.debug("Calculating something for: {}", myObject);
}
- Natomiast gdy dany napis (jako argument) jest tworzony tylko i wyłącznie na potrzeby logowania, a jego uzyskanie zajmuje więcej czasu, można go objąć w klauzulę if, na przykład:
if (logger.isDebugEnabled()) {
logger.debug("Incomming request: {}", request.getMethod() + ", " + request.getParams());
}
Poza skrajnymi przypadkami w postaci wolnego dostępu do chaotycznie działającego dysku lub skrajnych wymagań niefunkcjonalnych dotyczących latency nie rozważamy innych przypadków.
Logowanie w środowisku rozproszonym
Gdy nasze usługi pracują w środowisku rozproszonym, problematyczne staje się przeglądanie logów z wielu hostów. Rozwiązać ten problem można wykorzysując scentralizowane logowanie. Tu istnieją dwa podejścia:
- Logi są wysyłane standardowo do pliku, w tle działa program śledzący pliki, który przesyła je do centralnego zbioru, np.: Logstash, Greylog, Splunk.
Plus: teoretycznie nie obciąża aplikacji. Minus: demon może się zawiesić. - Logi są wysyłane w centralne miejsce prosto z aplikacji.
Plus: większa pewność wysłania logów. Minus: obciążenie aplikacji.
Każde rozwiązanie należy przeanalizować do swojego przypadku użycia i zastosować takie, jakie nam odpowiada.
Podoba Ci się ten artykuł? Weź więcej.
Jeżeli uważasz ten materiał za wartościowy i chcesz więcej treści tego typu – nie przegap ich i otrzymuj je prosto na swoją skrzynkę. Nawiążmy kontakt.
Gdybyś potrzebował jeszcze więcej:
Jesteś Java Developerem?
Przejdź na wyższy poziom wiedzy
„Droga do Seniora” 🔥💪
Jesteś Team Leaderem? Masz zespół?
Podnieś efektywność i wiedzę swojego zespołu 👌
Zdjęcie: Designed by jcomp / Freepik
