Aby wykonywać operacje na bazie danych, trzeba najpierw się z nią połączyć i zestawić sesję. W Java najprostszym sposobem na podłączenie się do bazy jest zestawienie połączenia korzystając ze sterownika JDBC. Możesz też skorzystać z takich rozwiązań jak źródło danych czy pula połączeń.
Tworząc systemy, które wymieniają dane z bazą danych, chcesz, aby komunikacja była niezawodna. Możesz wykonywać operacje, które mogą być krótkie, ale za to częste, a może będziesz wykonywał takie, które są bardzo długie. Operacje są wykonywane w ramach nawiązanego wcześniej połączenia do bazy. Użytkowników systemu przeważnie jest wielu, a ich sesje powinny być niezależne.
W pewnym momencie może się zdarzyć, że użytkownik nie będzie mógł wykonać jakiejś operacji, ponieważ baza danych odrzuci kolejne połączenie ze względu na jakiś limit. Albo oprogramowanie, które korzysta z bazy danych, rzuci wyjątek ze względu na przekroczenie czasu oczekiwania na połączenie.
Z tego artykułu dowiesz się
- Czym jest źródło danych a czym pula połączeń i po co je stosować?
- Co możesz zyskać, jeśli będziesz używał puli połączeń lub źródła danych?
- W jaki sposób skorzystać z puli połączeń oraz źródła danych w Java?
- Jak konfiguracja puli połączeń lub źródła danych wpływa na stabilność działania Systemu?
Wydajność Hibernate
Twórz szybko działające aplikacje z wydajną i zoptymalizowaną obsługą bazy danych.

Zapotrzebowanie na połączenia
Użytkownicy Systemu wykonują przeważnie operacje, które skutkują komunikacją z bazą danych. W większości przypadków jest tak, iż w danym momencie tylko część z użytkowników aktywnie wykorzystuje bazę danych. Pozostali mogą np. czytać dane, które zostały wyświetlone, czy zastanawiać się co zrobić dalej. A może nawet nic w danym momencie nie robią, bo odeszli od komputera, ale są cały czas zalogowani do Systemu.
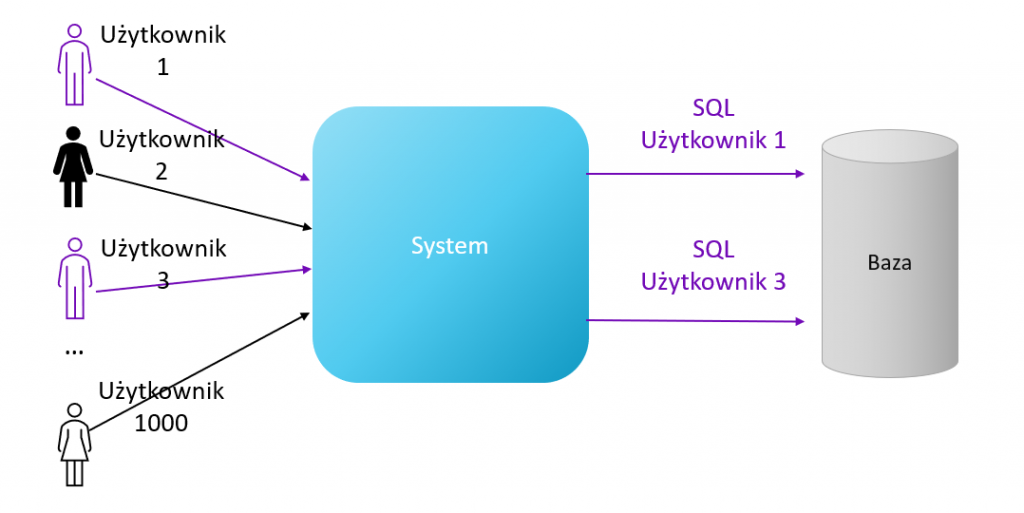
Baza danych może mieć ustawiony limit dla liczby aktywnych połączeń, po którego przekroczeniu, System będzie musiał oczekiwać w kolejce na zwolnienie się jakiegoś połączenia.
Limit można zwiększyć tylko do pewnych granic ze względu na fizyczne ograniczenia serwera bazy danych (pamięć, procesor, czas przetwarzania).
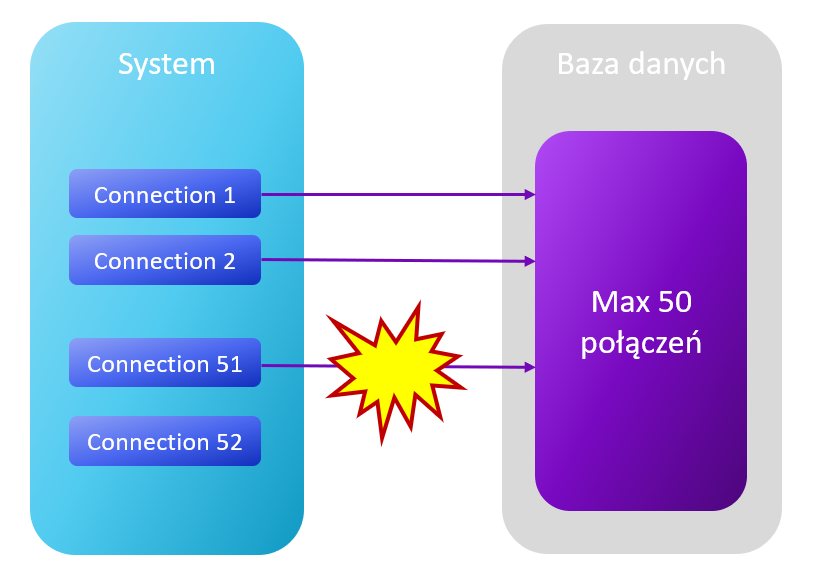
System może być także ograniczony ze względu na wymagania sprzętowe czy architektoniczne – np. możesz chcieć dynamicznie skalować system i w miarę potrzeb dodawać nowe lub usuwać niepotrzebne serwery. Takie serwery nie powinny nawiązywać zbyt dużej liczby połączeń, skoro mają być małe.
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
Używając wielu serwerów Systemu i mając ustawiony limit połączeń dla instancji, a nie tylko globalnie do bazy danych zabezpieczysz się przed odrzuceniem połączeń dla wszystkich serwerów. Jeśli baza danych odrzuci połączenie, to jest możliwość, że pozostałe serwery/instancje Systemu nadal będą działać prawidłowo.
Patrząc na powyższe widać, że:
- Liczba połączeń do bazy danych nie musi być równa liczbie zalogowanych użytkowników – może być mniejsza i odpowiadać możliwościom Systemu oraz bazy danych
- Liczby nawiązanych połączeń do bazy danych jest ograniczona
- System powinien w jakiś sposób zarządzać połączeniami – nawiązywać połączenia czy też je zwalniać tak, aby nie przekroczyć limitu. Musi istnieć jakiś mechanizm kolejkowania – pobieranie, oczekiwanie na swoją kolej, zwalnianie.
Musisz sobie także zdawać sprawę z kosztów połączenia po stronie Java – jeśli będzie ich dużo, to koszt także będzie większy.
Zwiększanie liczby połączeń niesie za sobą koszty – więcej pamięci, procesora i sieci i czasu
Źródło danych
Źródło danych to mechanizm, który zarządza aktywnymi połączeniami do bazy danych:
- Nawiązuje połączenie do bazy danych.
- Może posiadać limit aktywnych połączeń.
- Pozwala na zwalnianie połączeń do bazy danych.
- Może posiadać dodatkową parametryzację, np.:
- Limit czasu oczekiwania na rezerwację połączenia,
- Liczba wstępnie nawiązanych połączeń.
- Liczba połączeń w gotowości (zawsze musi być tyle niewykorzystanych, ale nawiązanych połączeń).
- Maksymalny czas nieaktywności.
- Maksymalny czas życia.
- Cache zapytań/wyrażeń.

JDBC API dostarcza interfejsu javax.sql.DataSource, który reprezentuje źródło danych. Definiuje on zaledwie kilka metod i spośród wymienionych powyżej dostarcza dwóch:
getConnection– nawiązuje nowe połączenie.setLoginTimeout– maksymalny czas oczekiwania na nawiązanie połączenia.
Ale DataSource to tylko interfejs i konieczne jest dostarczenie implementacji. A same implementacje umożliwiają już trochę więcej.
DataSource dedykowany dla bazy danych
Implementacje mogą być dostarczane przez dostawców baz danych – są dedykowane dla konkretnego rodzaju bazy danych. Zakres dostępnej konfiguracji dla poszczególnych dostawców jest różny (ale jak wspomniałem wcześniej – interfejs DataSource definiuje zaledwie kilka metod).
Przykładem może być baza H2 i klasa org.h2.jdbcx.JdbcDataSource. Zakres konfiguracji obejmuje parametry połączenia do bazy danych oraz czas oczekiwania na logowanie – nie ma np. limitu liczby połączeń.
- H2 – zależność maven
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>1.4.200</version>
</dependency>
- H2 – przykład tworzenia DataSource
var dataSource = new JdbcDataSource();
dataSource.setURL("jdbc:h2:mem:softwareskill_orm;TRACE_LEVEL_SYSTEM_OUT=3");
dataSource.setLoginTimeout(1000);
var connection = dataSource.getConnection();
Innym przykład dla bazy danych PostgreSQL i implementacja org.postgresql.ds.PGSimpleDataSource. Ma ona więcej możliwości konfiguracji niż H2, ale nadal nie ma możliwości ustawienia limitu aktywnych połączeń.
- PostgreSQL – zależność maven
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.2.18</version>
</dependency>
- PostgreSQL – przykład tworzenia DataSource
var dataSource = new PGSimpleDataSource();
dataSource.setURL("jdbc:postgresql:softwareskill?loggerLevel=trace");
dataSource.setUser("softwareskill");
dataSource.setPassword("softwareskill");
dataSource.setConnectTimeout(500);
dataSource.setSocketTimeout(1000);
dataSource.setLoginTimeout(1000);
dataSource.setPreparedStatementCacheQueries(100);
dataSource.setTcpKeepAlive(true);
Uniwersalne implementacje DataSource
Istnieją także osobne implementacje DataSource, które opakowują klasyczne połączenie do bazy danych lub inny DataSource, dostarczając dodatkowej funkcjonalności.
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
Przykładem jest Hikari i klasa com.zaxxer.hikari.HikariDataSource. Dla tej implementacji jest już możliwość zdefiniowania limitu aktywnych połączeń – metoda setMaximumPoolSize. Możesz też ustawić czas nieaktywności albo maksymalny czas życia dla połączenia, po których przekroczeniu, połączenie zostanie zamknięte i źródło danych będzie mogło nawiązać kolejne nowe połączenie.
Musisz pamiętać o tym, aby dostarczyć innego właściwego sterownika lub DataSource dla Hikari .
- Hikari – zależność maven
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>3.4.5</version>
</dependency>
- Hikari + PostgreSQL dla opakowanego połączenia – przykład Java
var dataSource = new HikariDataSource();
dataSource.setDriverClassName("org.postgresql.Driver");
dataSource.setJdbcUrl("jdbc:postgresql:softwareskill?loggerLevel=trace");
dataSource.setUsername("softwareskill");
dataSource.setPassword("softwareskill");
dataSource.setMaximumPoolSize(10);
var connection = dataSource.getConnection();
- Hikari + PostgreSQL dla opakowanego datasource – przykład Java
var dataSource = new HikariDataSource();
dataSource.setDataSourceClassName("org.postgresql.ds.PGSimpleDataSource");
dataSource.setJdbcUrl("jdbc:postgresql:softwareskill");
dataSource.setUsername("softwareskill");
dataSource.setPassword("softwareskill");
dataSource.setMaximumPoolSize(10);
dataSource.setMinimumIdle(2);
dataSource.setMaxLifetime(1000);
dataSource.setIdleTimeout(1000);
var connection = dataSource.getConnection();
Blokowanie/korzystanie z nawiązanego połączenia
Każda z operacji, jakie chcesz wykonać na bazie z wykorzystaniem nawiązanego wcześniej połączenia, składa się z kilku kroków:
- Pobranie połączenia.
- Przygotowanie instrukcji SQL (
java.sql.Statementlub pochodne). - Rozpoczęcie transakcji, jeśli jest ona konieczna.
- Wysłanie i wykonanie instrukcji SQL (metoda
execute*). - Opcjonalne pobranie wyników (
java.sql.ResultSet). - Zwolnienie zasobów:
- Dla wyniku (jeśli był).
- Dla instrukcji.
commit/rollback– jeśli transakcja aktywna.- Zwolnienie połączenia.
Każdy z tych kroków trwa jakiś czas i przez ten cały czas połączenie jest wykorzystywane. Ponieważ sesje użytkowników powinny być niezależne, to w tym samym momencie z tego połączenia nikt inny nie powinien korzystać.
Z limitu aktywnych połączeń na cały ten czas „wypada” to połączenie.
Do każdego z tych kroków można przypisać czas i zweryfikować ile każdy z nich zajmuje. W zależności od tego, co będzie realizowane narzut czasowy i procentowy udział poszczególnych kroków może być różny. Jeżeli będziesz pobierał bardzo dużo danych, to sumaryczny czas będzie duży.
Cierpliwość/timeout/czas oczekiwania
System może mieć ustawiony limit czasowy (timeout) oczekiwania na połączenie. Użytkownik Systemu także ma skończoną cierpliwość i nie będzie czekał w nieskończoność. System powinien wyświetlić po jakimś czasie informację o niemożności wykonania operacji, aby użytkownik wiedział, że coś jest nie tak i mógł spróbować za chwilę.
Re używanie połączeń
Powyżej wspomniałem o krokach, z których składa się operacja na bazie danych. Co, jeśli operacje będą szybkie, a tak może być w najczęstszym przypadku. Narzut związany z nawiązaniem i zwalnianiem połączenia może okazać się procentowo bardzo duży.
Jest to pewna analogia do logowania do systemu, gdzie sam proces nawiązania połączenia trwa długo:
- Połączenie może być szyfrowane np. SSL – konieczne jest zestawienie połączenia z serwerem, weryfikacja certyfikatu, szyfrowanie kanału
- Po połączeniu pobierane są dane odnośnie uprawnień i na ich podstawie wyświetlone dostępne użytkownikowi funkcjonalności, pozycje menu, formatki etc.
Podobnie jest z bazą danych – trzeba nawiązać połączenie, może być ono także szyfrowane. Połączenie może być specyficznie sparametryzowane co może się wiązać z dłuższym czasem przetwarzania. Użytkownik techniczny, którego wykorzystuje System musi zostać zweryfikowany – nazwa, hasło i uprawnienia, ustawione zostają parametry sesji.
Wszystko to trwa.
A co jeśli mógłbyś skorzystać z nawiązanych wcześniej połączeń i zamiast je zamykać -odzyskać je jako „wyczyszczone”.
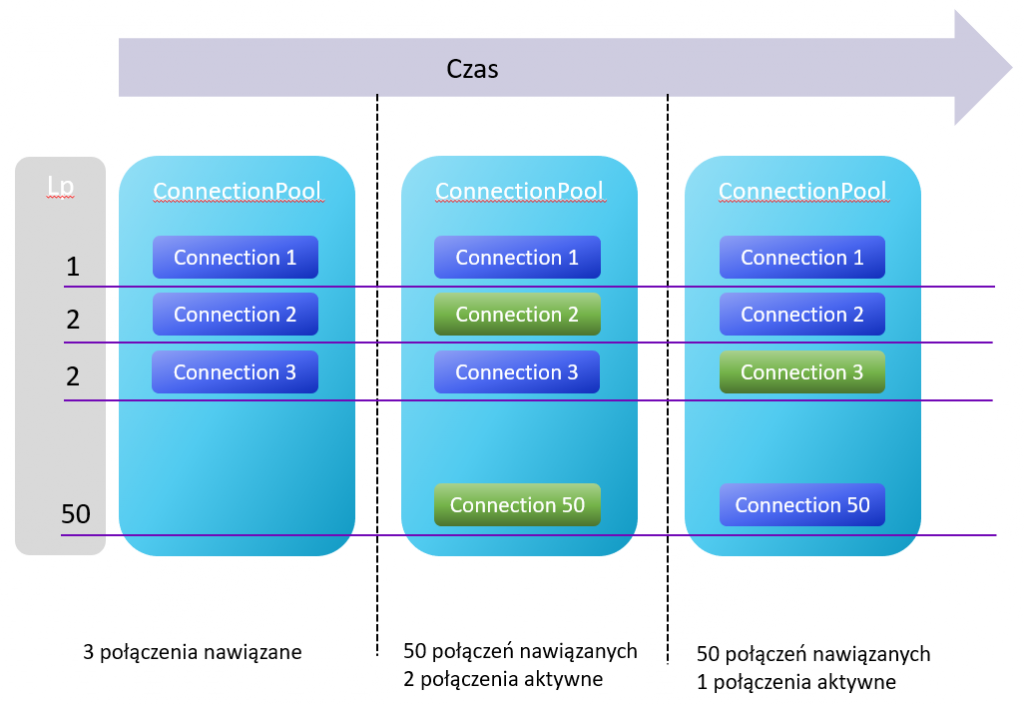
Pula połączeń jest właśnie tym, czego możesz użyć, aby skorzystać z funkcjonalności re używania nawiązanych połączeń.
Pula połączeń
Pula połączeń jest podobna do źródła danych i dodaje możliwość ponownego wykorzystania nawiązanych już połączeń. Połączenia zamiast być zamykane – są „odzyskiwane” – wykorzystywany jest mechanizm czyszczenia tak, aby pozostałości po poprzednim użyciu zostały wyczyszczone – wywoływany jest np. rollback oraz czyszczenie ostrzeżeń clearWarnings interfejsu java.sql.Connection.
Uwaga!!!. Jeżeli stosujesz jakieś specyficzne ustawienia dla bazy danych – np. jakaś zmienna sesji użytkownika, to może się zdarzyć, że wartość nie zostanie wyczyszczona.
Czy odzyskiwanie połączeń działa?
Przeważnie jest tak, że baza danych umożliwia odpytanie o aktywne sesje i będziesz w stanie sprawdzić, czy połączenia odzyskują się, czy tylko powstają nowe. Musisz jednak pamiętać o tym, że mogą działać inne mechanizmy czyszczące lub optymalizujące i będą się pojawiały nowe połączenia.
Przykład zapytania dla bazy PostgreSQL
select pid as process_id,
usename as username,
datname as database_name,
client_addr as client_address,
application_name,
backend_start,
state,
state_change
from pg_stat_activity order by pid
Interfejsy dla puli połączeń w JDBC API
JDBC API dostarcza interfejsu PooledConnection pakietu javax.sql – definiuje on połączenie, które może być odzyskiwane. Nie dziedziczy on z java.sql.Connection – można je pobrać poprzez metodę getConnection i wymieniać dane z bazą danych.
Z kolei interfejs ConnectionPoolDataSource tego samego pakietu (javax.sql) definiuje fabrykę dla połączeń, które będą mogły być „odzyskiwane”. Nie dziedziczy on z javax.sql.DataSource.
Podobnie jak w przypadku ze źródłem danych – dla interfejsu musi być dostarczona implementacja. Może być ona dedykowana dla konkretnego rodzaju bazy danych i dostarczana w ramach sterownika JDBC. Można skorzystać także z dostępnych bibliotek dostarczających źródło danych wspierające re używalne połączenia.
Pula połączeń dla konkretnej bazy danych
Producenci baz danych, firmy trzecie lub środowiska OpenSource mogą dostarczać implementacji źródła danych, które wspiera odzyskiwanie połączeń. Może być ona dostarczona w ramach biblioteki ze sterownikiem JDBC.
Może się zdarzyć, że będzie implementacja ConnectionPoolDataSource oraz PooledConnection.
Ale może być tak, że będzie tylko implementacja DataSource (w sensie dziedziczenia Java). A funkcjonalność będzie umożliwiała odzyskiwanie połączeń – np. metoda close odzyska połączenie.
- Przykład dla bazy PostgreSQL – implementacja
ConnectionPoolDataSource. Ta klasa nie ma możliwości ustawiania liczby połączeń.
var dataSource = new PGConnectionPoolDataSource();
dataSource.setURL("jdbc:postgresql:softwareskill?loggerLevel=trace");
dataSource.setUser("softwareskill");
dataSource.setPassword("softwareskill");
dataSource.setDefaultAutoCommit(false);
var connection = dataSource.getPooledConnection();
- Przykład dla bazy PostgreSQL – implementacja
DataSource. Dla tej klasy masz możliwość sterowania liczbą połączeń. Mimo że nie implementuje interfejsuConnectionPoolDataSource,to dostarcza funkcjonalności odzyskiwania połączeń
var dataSource = new PGPoolingDataSource();
dataSource.setDatabaseName("softwareskill");
dataSource.setURL("jdbc:postgresql:softwareskill?loggerLevel=trace");
dataSource.setUser("softwareskill");
dataSource.setPassword("softwareskill");
dataSource.setMaxConnections(10);
dataSource.setInitialConnections(10);
var connection = dataSource.getConnection();
W takim przypadku następuje pewne wymieszanie pojęć, bo klasa nie dziedziczy z ConnectionPoolDataSource.
Uniwersalne implementacje puli połączeń
Możesz też skorzystać z puli połączeń, która jest uniwersalna i może działać z różnymi bazami danych.
Podobnie jak w przypadku dedykowanych dla konkretnej bazy implementacja może dziedziczyć z ConnectionPoolDataSource, ale niekoniecznie tak będzie.
W zależności od konfiguracji implementacja może działać w ten sposób, iż nie będzie odzyskiwać połączeń a tylko tworzyć nowe i pilnować maksymalnej liczby nawiązanych połączeń.
Przykład Hikari – wcześniej w artykule masz fragmenty kodu, gdzie tworzona jest pula na dwa sposoby:
- z wykorzystaniem klasy sterownika JDBC – metoda
setDriverClassName– ten sposób pozwoli sterować jedynie liczbą połączeń, - z wykorzystaniem klasy DataSoure – metoda
setDataSourceClassName– dla tego rodzaju dodatkowo działać będzie odzyskiwanie połączeń.
Pula połączeń w ramach frameworka albo serwera
Korzystając z frameworków, może się zdarzyć, że pod spodem wykorzystują one jakąś funkcjonalność puli połączeń – np. Spring.
Podobnie z serwerami – np. Tomcat czy JBoss.
Analogicznie, jak wcześniej istnieje dla nich konfiguracja, dzięki której będziesz w stanie w jakimś stopniu zoptymalizować działanie. Albo będziesz mógł wstrzyknąć skonfigurowany przez Ciebie obiekt puli połączeń.
Higiena połączenia
W zależności od możliwości implementacji źródła danych czy puli połączeń możliwe jest definiowanie pewnych dodatkowych parametrów, które wpływają na stabilność działania Systemu.
Jeżeli połączenie zostanie zerwane, a nie zostanie to na czas wykryte, to w puli będzie nieaktywne połączenie. Zamiast pobrać kolejne na nowo zestawione, zostanie zwrócone uszkodzone i wystąpi wyjątek.
Implementacje często mają dodatkowe asynchroniczne mechanizmy, które pozwalają na walidację lub podtrzymanie połączenia, aby nie zostało zerwane przez bazę danych.
W obecnych systemach problemy z siecią są rzeczą naturalną i System musi być odporny na chwilowe zaniki połączenia. Nie powinieneś pozwolić na to, aby nagle wszystkie połączenia w puli zostały w jakiś sposób zerwane czy uszkodzone.
Musisz działać bardziej proaktywnie i zastosować mechanizmy, które zwiększą odporność na chwilowe zaniki, a także zmniejszą czas konieczny na odzyskanie pełni wydajności.
Ustawianie dodatkowych parametrów może pozwolić Ci na osiągnięcie tego celu:
- min idle connections – minimalna liczba połączeń gotowych do użycia – wiesz że nawiązanie połączenia trwa dość długo. Jeśli nawiążesz je wcześniej, to od razu zostaną zwrócone, a mechanizmy działające w tle spróbują uzupełnić brak asynchronicznie.
- initial connections – liczbą nawiązanych połączeń na początku, zanim jeszcze zostanie aktywowana pula. Może działać to synchronicznie. Jeżeli wiesz, że wystarczy Ci mieć w zapasie 5 połączeń, ale na start musisz mieć 20, to można tym parametrem skrócić czas dostępu dla użytkowników zaraz po restarcie Systemu.
- keep alive/keep alive query/probe query – mechanizm wysyłania jakiejś instrukcji lub ponownej komunikacji z bazą, który podtrzyma połączenie i ew. wykryje to, że połączenie zostało zerwane lub jest jakiś inny błąd. Dzięki temu połączenie wypadnie z puli i nikt nie trafi na taką uszkodzoną sesję
- socket timeout – limit czasu dla połączenia, mogą zdarzać się pewne chwilowe zaniki i niekoniecznie chwilowe spowolnienie oznaczać musi zerwanie połączenia. Ustawiając ten limit do odpowiedniego poziomu można poprawić sytuację – niekoniecznie tylko zwiększając, ale także zmniejszając (jest przecież jeszcze probe query)
- max life time – maksymalny czas życia – niekiedy stosuje się takie rozwiązanie, aby zwolnić długo nawiązane połączenie, aby odświeżyć listę połączeń
- max idle time – maksymalny czas nieaktywności – służy do dodatkowego odzyskiwania nieaktywnych połączeń. Np. użytkownik mógł zamknąć aplikację w sposób niekontrolowany (zamknięcie procesu, restart systemu, „krzyżyk” w przeglądarce) i połączenie będzie „wisiało” przez jakiś czas. Nie zawsze czas życia sesji aplikacji (np. WWW) wystarczy. Jeśli np.
- Jest ustawiony na 30 s.
- Została rozpoczęta transakcja.
- Połączenie jest w puli.
- Dopiero po tych 30 s nastąpi zwolnienie połączenia, ze względu na zamknięcie sesji WWW.
Podsumowanie
Pula połączeń i źródło danych występują często razem. Różnica wynika z tego, jakiej definicji chcesz się trzymać.
Najważniejsze, żebyś wiedział co chcesz osiągnąć – czy chcesz odzyskiwać połączenia, czy też tego nie chcesz.
Możesz zabezpieczyć się przed niekontrolowanym wzrostem liczby aktywnych połączeń po stronie Java i bazy danych. Możesz przyspieszyć wymianę danych, korzystając z wcześniej nawiązanych połączeń.
Jeśli użyjesz puli połączeń, to dodatkowo zaoszczędzisz czas na nawiązywanie i zwalnianie połączenia.
Mechanizmy te ze względu na dodatkową funkcjonalność mają pewien narzut czasowy. Ale re używanie połączeń może być szybsze niż nawiązywanie i zamykanie połączeń.
Przez odpowiednią konfigurację będziesz w stanie zoptymalizować szybkość działania Systemu w zakresie dostępu do nawiązanego połączenia do bazy danych.
Zwiększysz także odporność na chwilowe zaniki sieci.
Wpis który czytasz to zaledwie fragment wiedzy zawartej w Programie szkoleniowym Java Developera od SoftwareSkill. Mamy do przekazania sporo usystematyzowanej wiedzy z zakresu kluczowych kompetencji i umiejętności Java Developera. Program składa się z kilku modułów w cotygodniowych dawkach wiedzy w formie video.
Wydajność Hibernate
Twórz szybko działające aplikacje z wydajną i zoptymalizowaną obsługą bazy danych.
Podoba Ci się ten artykuł? Weź więcej.
Jeżeli uważasz ten materiał za wartościowy i chcesz więcej treści tego typu – nie przegap ich i otrzymuj je prosto na swoją skrzynkę. Nawiążmy kontakt.
Gdybyś potrzebował jeszcze więcej:
Jesteś Java Developerem?
Przejdź na wyższy poziom wiedzy
„Droga do Seniora” 🔥💪
Jesteś Team Leaderem? Masz zespół?
Podnieś efektywność i wiedzę swojego zespołu 👌
