Chyba każdy zna to uczucie. Chcemy coś przetestować, albo zbliża się release i … środowisko nie działa. Nasza aplikacja ma zależność – albo do bazy danych, albo do brokera wiadomości, albo do innej części infrastruktury. I co teraz? Jest jakaś metoda, aby z jednej strony wyizolować infrastrukturę, ale z drugiej nie mieć wszystkiego zamockowane, albo w implementacjach in-memory i jednak przetestować te interakcje?
W tym wpisie chciałbym polecić Twojej uwadze projekt Testcontainers. Podejdziemy do tematu z różnych perspektyw.
Praktycznie każda aplikacja realizująca logikę biznesową ma zależność jakiejś infrastruktury. Najczęstsze przykłady:
- Aplikacja przechowuje stan – zależność do bazy danych
- Komunikacja asynchroniczna – zależność do brokera wiadomości
- Testy aplikacyjne na uruchomionej aplikacji – zależność do środowiska uruchomieniowego
- Aplikacja potrzebuje danych lub zleca operacje – zależność do innego serwisu albo usługi
Zgodnie z piramidą testów, te punkty styku testujemy w testach integracyjnych – ze względu na stosunkowo wysoki koszt ich uruchomienia spowodowany potencjalną niestabilnością środowiska i I/O. Możemy zredukować koszt uruchomienia i stabilności testów korzystając z implementacji „w pamięci” (in-memory).
O ile zależności do innej usługi możemy ograniczyć w testach stosując zaślepki typu Wiremock (auto-generowane w Spring Cloud Contract w podejściu Consumer-Driven Contract), o tyle interakcje z infrastrukturą chcielibyśmy przetestować, bo są najczęściej zależne są od konkretnej technologii (nie jest to ustandaryzowany REST).
Stabilność środowiska i testów
Testując integracyjnie potrzebujemy działającej instancji komponentu, na którym można przeprowadzić test. Jest to na przykład działający broker wiadomości albo działająca baza danych. Problem z tego typu komponentem jest taki, że zazwyczaj jest jeden i pojawia się kilka wyzwań.
1. Dostępność i stabilność
Po pierwsze, to środowisko musi być dostępne i stabilne. Czyli baza danych musi działać, broker musi być uruchomiony. Nie może zabraknąć miejsca na dysku. To powoduje, że testy mogą zgłosić błąd nie tylko ze względu na pojawienie się regresji, ale także na niestabilne środowisko.
2. Spójność danych – pozostałości i kilka runów jednocześnie
Testy powinny być odpowiednio zaprojektowane, aby nie przeszkadzały sobie nawzajem pomiędzy uruchomieniami. Zgodnie z zasadą powtarzalności (Repeatable z dobrych praktyk pisania testów F.I.R.S.T.), kolejne uruchomienie zestawu testów nie powinny dawać odmiennych rezultatów – tym samym testy są stablilne. Aby uniknąć działania na „cudzych” danych, testy mogą na przykład czyścić po sobie dane w bazie danych, albo czyścić kolejkę wiadomości przed wykonaniem testów. Jest to pewien dodatkowy nakład pracy i dodatkowa rzecz do przemyślenia podczas projektowania zestawu testów.
Podejmując ten wysiłek nie oznacza, że testy będą stabilne. Wciąż może dojść do sytuacji, że zestaw testów zostanie uruchomiony kilka razy w tym samym czasie, na przykład dla osobnych branchy. Wtedy testy zaczną ze sobą interferować, na przykład zapytania agregujące mogą zwracać błędne sumy, albo testy będą konsumować nie swoje komunikaty z brokera wiadomości.
3. Wersjonowanie
Z bazą danych można trafić na przypadek, kiedy „jedna” baza danych i schema ma różną strukturę. Na bieżącej głównej gałęzi jest schemat v.1, a chcemy przetestować zmianę wprowadzającą schemat v.2, który jest niekompatybilny z v.1. Oczywiście, w normalnej sytuacji nastąpi migracja. Natomiast w zależności od schematu na bazie nie możemy uruchomić jednego, albo drugiego zestawu testów.
Sytuacja rzadka, ale prowadzi do niestabilności testu tylko dlatego, że istnieje jeden schemat do testów integracyjnych.

Implementacje in-memory
Aby zredukować koszt związany z szybkością działania testów integracyjnych oraz ich stabilnością, można zejść poziom niżej w piramidzie testów do testów komponentowych lub unitowych i użyć implementacji pamięciowych (in-memory). Są to implementacje symulujące działanie elementów infrastruktury działając w pamięci, czyli bez komunikacji do zewnętrznego środowiska.
Przykładem może być działający w pamięci broker wiadomości ActiveMQ (czytaj więcej), albo baza danych H2 Database (czytaj więcej) zgodny ze standardem SQL oraz standardem JDBC.
Te implementacje mogą być w pełni wystarczające na potrzeby naszego projektu.
Natomiast możemy korzystać z tych możliwości bazy danych które znacznie przekraczają standard SQL lub korzystać z infrastruktury, do której implementacji in-memory nie ma, a jednak wciąż mamy apetyt automatycznego przetestowania tej części aplikacji.
Przykładem mogą być specyficzne składnie albo funkcje agregujące w Oracle, albo rozszerzenia PostGIS w PostgreSQL. Przykłady mogą wydawać się Tobie abstrakcyjne, ale możesz trafić przypadek, gdzie implementacje in-memory nie są wystarczające, a jednak jest apetyt na automatyzowanie regresji w tym zakresie.
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
Projekt Testcontainers
Testcontainers to biblioteka, która w ramach testów JUnit pozwala na uruchomienie tymczasowych kontenerów Dockerowych, na których mogą zostać przeprowadzone testy.
Ideą jest przygotowanie świeżego, stabilnego środowiska, które może być usunięte po wykonaniu zestawu testów. Można uruchomić dowolny kontener, np. bazę danych, brokera wiadomości, albo nawet naszą aplikację, którą możemy przetestować „z zewnątrz” w warstwie testów aplikacyjnych/akceptacyjnych.
Zaletą jest:
- Dynamicznie alokowane, dedykowane środowisko – brak interferowania testów między sobą
- Czysty stan – brak niepożądanych danych
- Stabilne, tymczasowe środowisko – zawsze dostępne zasoby
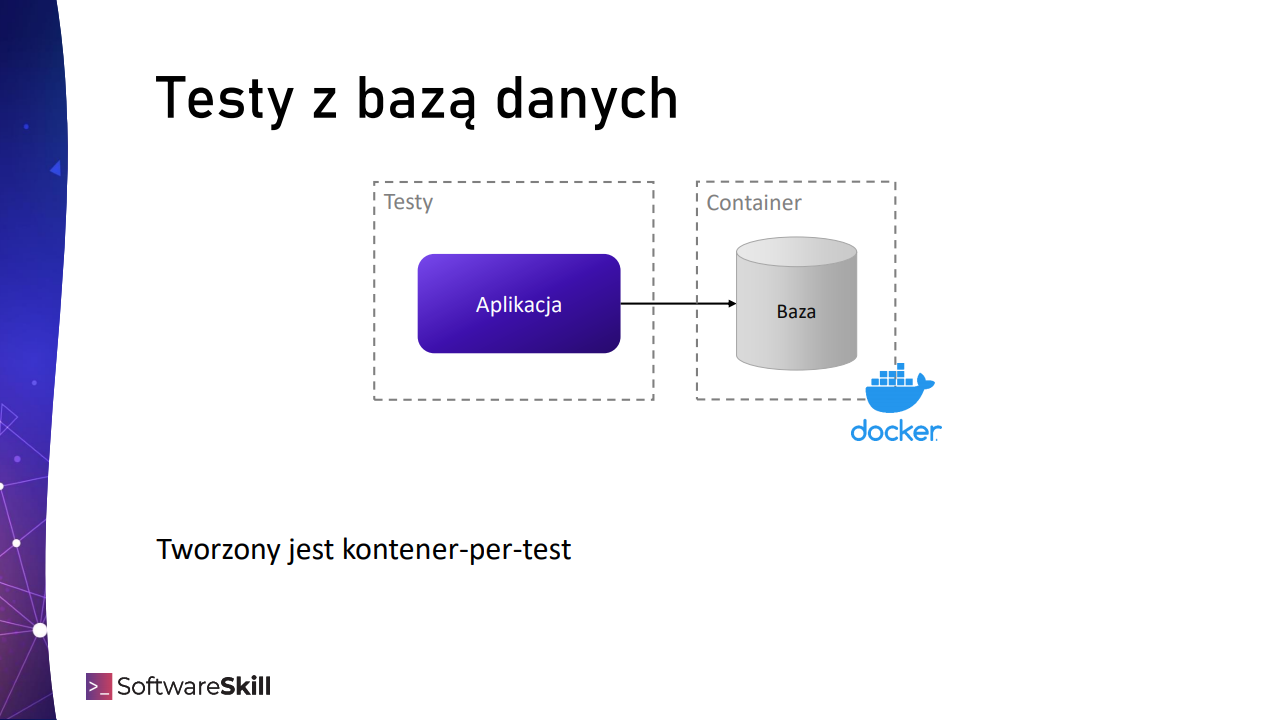
I teraz:
- Zamiast testować mapowanie i zapytania do bazy danych z bazą danych H2, która emuluje zachowanie bazy SQL – możesz testować z prawdziwą bazą danych.
- Zamiast testować z zależnością uruchomioną na wirtualnej maszynie (baza, broker) – możesz testować na realnej infrastrukturze.
Sam projekt zawiera już konfigurację z wieloma popularnymi bazami danych oraz brokerami wiadomości, serwerami i innymi rozwiązaniami, które autorzy nazywają modułami.
Przykład
Przetestuję warstwę zachowania stanu (mapowanie JPA) na realnie działającej bazie danych.
Aby skorzystać z projektu Testcontainers definiujemy dwie zależności:
<dependency>
<groupId>org.testcontainers</groupId>
<artifactId>testcontainers</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testcontainers</groupId>
<artifactId>junit-jupiter</artifactId>
<scope>test</scope>
</dependency>
Dodatkowo, będę wykorzystywał bazę danych MySQL, dlatego dodaję jeszcze dwie zależności:
- definicję kontenera mysql, zawiera informacje takie jak:
- healthcheck – jak sprawdzić, czy usługa uruchomiona w kontenerze już jest dostępna przed uruchomieniem testów wykonując testowe zapytanie
- użycie wyeksportowanych portów
- driver mysql – testcontainers nie dostarcza sterowników JDBC, deklarujemy je osobno
<dependency>
<groupId>org.testcontainers</groupId>
<artifactId>mysql</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.25</version>
</dependency>
Teraz pora wykorzystać uruchomiony kontener bazy danych.
Konfiguracja
Dla aplikacji w Spring Boot tworzę nowy plik application-testcontainers.properties. Tutaj znajdą się dane konfiguracyjne dla profilu uruchomieniowego „testcontainers„. Wewnątrz definiuję datasource:
spring.datasource.url=jdbc:tc:mysql:5.7.34:///test?TC_INITSCRIPT=schema.sql
spring.datasource.driver-class-name=org.testcontainers.jdbc.ContainerDatabaseDriver
spring.datasource.username=test
spring.datasource.password=test
spring.jpa.database-platform=org.hibernate.dialect.MySQL57Dialect
Powyższy fragment kodu definiuje driver JDBC o nazwie ContainerDatabaseDriver.
To bardzo wygodna metoda integracji Spring Data i JDBC z Testcontainers. Na podstawie URL JDBC driver pobiera oraz uruchamia kontener w wybranej wersji na losowym wolnym porcie.
Nie musimy ręcznie konfigurować kontenera do uruchomienia szukając wolnego portu oraz wstrzykiwać uzyskanego adresu do propertiesów aplikacji. Dzięki temu driverowi JDBC, połączenie jest po prostu dostępne po uruchomieniu kontenera.
Alternatywnie musielibyśmy uruchomić kontener w kodzie, uzyskać numer zaalokowane portu, zbudować URL JDBC oraz wstrzyknąć go do propertiesów uruchomionego kontekstu springa, aby driver mógł utowrzyć połączenie. Dostajemy to „za darmo” dzięki ContainerDatabaseDriver .
Testy
W testach korzystamy z adnotacji @Testcontainers, resztę mamy zadeklarowaną w pliku properties, który zostanie załadowany przez Spring Boot.
Przykładowy test:
@SpringBootTest(classes = PersistenceConfig.class)
@EnableAutoConfiguration
@ActiveProfiles("testcontainers")
@Testcontainers
@Tag("integration")
public class PersistenceTestcontainersTest {
@Autowired
BasketRepository basketRepository;
@Autowired
ProductRepository productRepository;
@Test
void savesBasketWithoutError() {
// given
var basket = make(a(BasketWithProducts));
// then
basketRepository.save(basket);
}
}
Uruchamiay test.
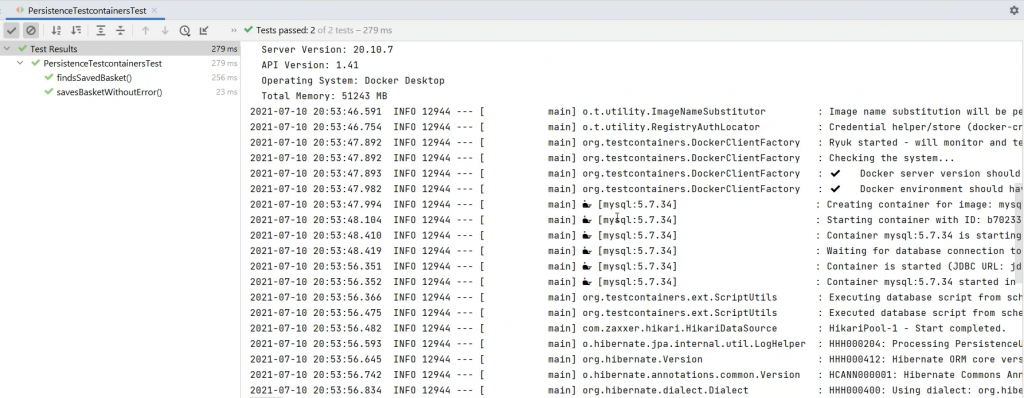
Podczas uruchamiania widzimy, że w tle wystartował jeden kontener koordynujący oraz baza danych mysql:
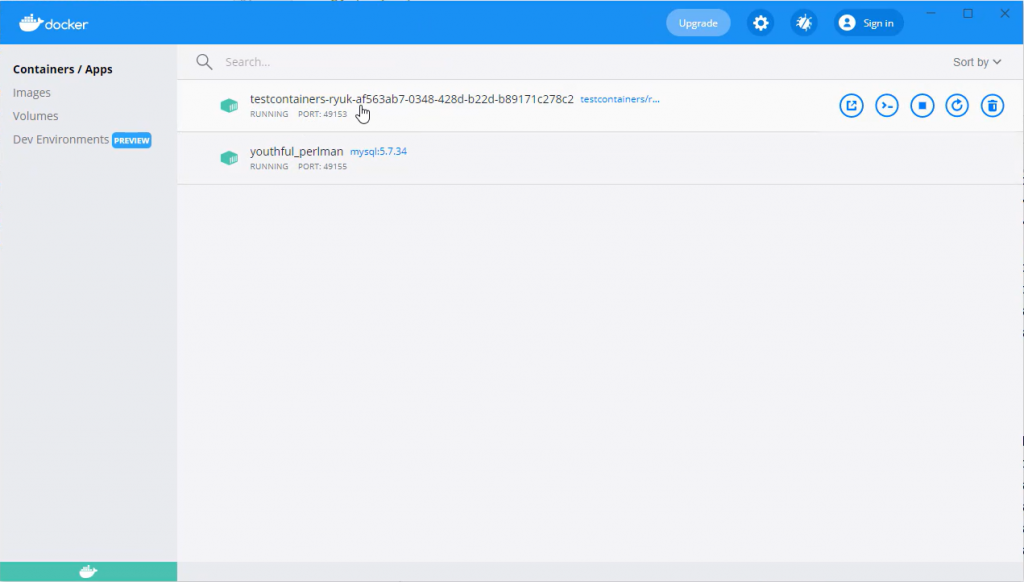
Kontener został wystartowały, a port bazy mysql 3306 został wyeksponowany dla aplikacji na losowym porcie.
Następnie został uruchomiony skrypt schema.sql, po czym wszystkie testy, które korzystały z realnej bazy danych.
Na sam koniec kontenery zostały zatrzymane.
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
Podsumowanie
Projekt Testcontainers pozwala na uruchmienie stabilnego, dostępnego, czystego środowiska do przetestowania integracji z infrastrukturą. Eliminuje problem dostępności środowiska tworząc je dynamicznie na potrzeby testów. Dodatkowo, osobne uruchomienia testów z różnych branchy nie przeszkadzają sobie nawzajem (nie interferują).
Sam proces może trwać nieco dłużej od implementacji in-memory, ale daje możliwości przetestowania integracji aplikacji tam, gdzie zaślepki in-memory nie są wystarczające.
Do czego jeszcze można wykorzystać Testcontainers?
- Do testów aplikacyjnych/akceptacyjnych. Nasza aplikacja może uruchomić się w kontenerze, a zestaw testów się na niej wykona.
- Do testów integracyjnych – wszelkiej maści.
- Do testów z bazą danych – jak wspomniano w tym artykule.
- Do uruchomienia dowolnego kontenera za pomocą GenericContainer.
Podoba Ci się ten artykuł? Weź więcej.
Jeżeli uważasz ten materiał za wartościowy i chcesz więcej treści tego typu – nie przegap ich i otrzymuj je prosto na swoją skrzynkę. Nawiążmy kontakt.
Piguła wiedzy o najlepszych praktykach testowania w Java
Pobierz za darmo książkę 100 stron o technikach testowania w Java

Wpis który czytasz to zaledwie fragment wiedzy zawartej w Programie szkoleniowym Java Developera od SoftwareSkill. Mamy do przekazania sporo usystematyzowanej wiedzy z zakresu kluczowych kompetencji i umiejętności Java Developera. Program składa się z kilku modułów w cotygodniowych dawkach wiedzy w formie video.
