Hibernate jest rozbudowanym narzędziem ułatwiającym pracę z bazami danych w Java. Wiele operacji wykonywanych jest „auto magicznie”. Możesz mieć wrażenie, że „To” działa samoistnie oraz szybko i wydajnie.
Nieznajomość specyfiki narzędzia może doprowadzić do tego, że wydajność Twojej aplikacji spadnie dramatycznie.
➡️ Jeśli poznasz i zrozumiesz zasady działania, będziesz w stanie poprawić wydajność operacji związanych z komunikacją z bazą danych.
➡️ Wiedząc jak włączyć monitorowanie, zweryfikujesz czy zapytania wysyłane do bazy danych są tymi, których się spodziewałeś.
Z tego artykułu dowiesz się:
- Jak działa Lazy-Loading ⏱️ i czym różni się pobieranie LAZY od EAGER
- Poznasz jak to działa w różnych typach relacji 🤔
- Dowiesz się, jak poprawić wydajność aplikacji 💪:
- Eliminując N+1 problem
- Przy operacjach masowych
- Włączając diagnostykę i śledzenie zapytań SQL
- Pobierając tylko to, czego potrzebujesz
Wydajność Hibernate
Twórz szybko działające aplikacje z wydajną i zoptymalizowaną obsługą bazy danych.

Jak działa lazy loading?
Opóźnione ładowanie (lazy loading) w Hibernate działa w ten sposób, że odpowiednio oznaczone pola klasy są doczytywane z bazy danych dopiero przy pierwszej próbie odczytu danych innych niż klucz główny. Hibernate wykorzystuje tzw. proxy, które „przykrywa” klasę encji wywołując dodatkową logikę. Przykład encje Card i User, powiązane ze sobą relacją dwukierunkową typu lazy.
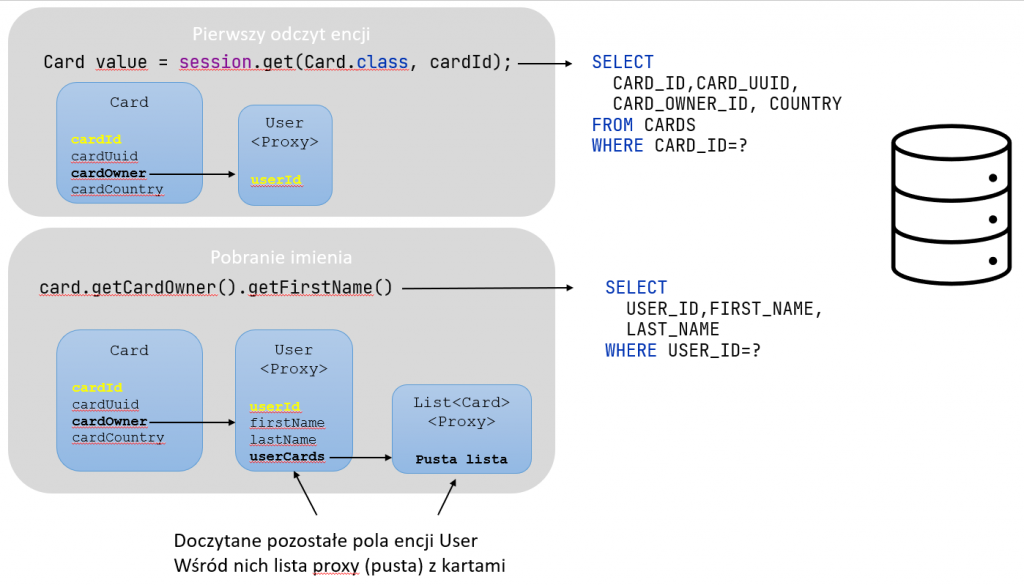
Opóźnione ładowanie dotyczyć może:
- Pola reprezentującego wartość kolumny tabeli.
- Kolekcji reprezentującej relację lub powiązane dane z innej tabeli.
Kod Java dla przykładu przytoczonego wcześniej

Dla porównania treść zapytania wygenerowanego przez Hibernate w przypadku, gdy:
- Wywołamy wyszukiwanie encji
Card–session.get(Card.class, cardId) - Zamiast
FetchType.LAZYzastosujemyFetchType.EAGER
select
card0_.CARD_ID as card_id1_0_0_,
card0_.COUNTRY as country2_0_0_,
card0_.CARD_OWNER_ID as card_own5_0_0_,
card0_.CARD_UUID as card_uui3_0_0_,
card0_.ENABLED as enabled4_0_0_,
user1_.USER_ID as user_id1_1_1_,
user1_.LAST_NAME as last_nam2_1_1_,
user1_.FIRST_NAME as first_na3_1_1_
from
CARDS card0_
left outer join
USERS user1_
on card0_.CARD_OWNER_ID=user1_.USER_ID
where
card0_.CARD_ID=?
Dla przypadku z użyciem FetchType.EAGER (po obydwu stronach relacji) nie będzie osobnego doczytania danych użytkownika dla pobrania imienia:
card.getOwner().getFirstName().
Stanie się to w jednym przebiegu – co widać w treści zapytania.
Lazy loading może poprawić lub pogorszyć wydajność aplikacji, zależy od tego, co w danym momencie chcesz zrobić.
Słynny problem N+1
Co to jest „problem N+1”?
Problem N+1 to sytuacja, w której dla każdego elementu z listy encji następuje wysłanie dodatkowego pojedynczego zapytania do bazy danych. Wyobraź sobie nasz przykład powyżej z kartami i użytkownikami.
- Wyszukujesz karty – wynik to 10 kart (jedno zapytanie SQL)
- Dla każdej z kart zostaje wysłane osobne zapytanie o właściciela (10 zapytań SQL).
W sumie wykonało się 11 zapytań – i to jest właśnie problem N+1 – dla każdego z rekordów wyniku (jest ich N) zostaje wywołane jedno dodatkowe zapytanie (+1).
Pojedyncze wykonywanie zapytań powoduje duży narzut czasu związany z komunikacją (dużo małych zapytań), a jeśli N jest duże, to aplikacja zaczyna spowalniać.
Kierunek relacji
Pierwszą rzeczą, którą należy uwzględnić, jest to czy relacja jest dwukierunkowa, czy jednokierunkowa.
Powyżej widziałeś przykłady dla relacji dwukierunkowej, dla której Hibernate w zależności od typu dociągania wygenerowało jedno lub dwa zapytania, dla pobrania danych o dwóch typach – encje Card i User.
Ustawienie dociągania danych dla relacji
Kolejną rzeczą jest zachowanie Hibernate dla dociągania relacji, a w szczególności domyślne wartości dla poszczególnych anotacji – właściwość fetch() o typie FetchType:
@OneToOne - default EAGER.@ManyToOne - default EAGER.@OneToMany - default LAZY.@ManyToMany - default LAZY.
Jak widać dwie pierwsze reprezentujące relacje jeden do jednego i wiele do jednego mają wartość EAGER, co spowoduje, iż dane zostaną dociągnięte od razu. Z kolei dwie pozostałe mają wartość domyślną LAZY. Musisz zachować czujność i upewnić się, że zachowanie dociągania relacji będzie właściwe (używając domyślnych wartości lub wymuszając odpowiednie).
Problem N+1 dla relacji typu EAGER
Dla doczytywania typu EAGER problem N+1 pojawia się dla relacji jednokierunkowej typu @OneToOne oraz @ManyToOne.
Podczas mapowania danych przez Hibernate dla każdej z encji Hibernate automatycznie wykona doczytanie danych – pojedynczo dla każdego z rekordów zostanie doczytana encja z relacji o ile nie istnieje w kontekście persystencji.
Mamy logikę wyszukiwania wszystkich kart dla kraju EA. W bazie danych jest 5 rekordów, każda z kart ma innego właściciela.

Dla wyszukiwania
public List<CardEagerUnidirectional> findAll() {
try {
return session.createQuery("FROM CardEagerUnidirectional where cardCountry='EA'",
CardEagerUnidirectional.class).getResultList();
} catch (Exception e) {
throw new DatabaseOperationException(e);
}
}
W konsoli zostaną wyświetlone następujące zapytania
[Hibernate] select cardeageru0_.CARD_ID as card_id1_0_, ..... from CARDS cardeageru0_ where cardeageru0_.COUNTRY='EA'
[Hibernate] select userunidir0_.USER_ID as user_id1_1_0_, ..... from USERS userunidir0_ where userunidir0_.USER_ID=?
[Hibernate] select userunidir0_.USER_ID as user_id1_1_0_, ..... from USERS userunidir0_ where userunidir0_.USER_ID=?
[Hibernate] select userunidir0_.USER_ID as user_id1_1_0_, ..... from USERS userunidir0_ where userunidir0_.USER_ID=?
[Hibernate] select userunidir0_.USER_ID as user_id1_1_0_, ..... from USERS userunidir0_ where userunidir0_.USER_ID=?
[Hibernate] select userunidir0_.USER_ID as user_id1_1_0_, ..... from USERS userunidir0_ where userunidir0_.USER_ID=?
Widać, że dla każdego z rekordów zostało wysłane dodatkowe zapytanie – w sumie 6 zapytań. Zapytania zostały wygenerowane automatycznie przez Hibernate w ramach mapowania danych.
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
Problem N+1 dla relacji typu LAZY
Geneza podobna jest do sytuacji z relacją jednokierunkową typu EAGER. Różnica polega na tym, że dodatkowe zapytanie zostaje wygenerowane dopiero w momencie próby odczytu danych z powiązanej encji (innych niż klucz główny) o ile nie istnieje w kontekście persystencji. Jest to opisane wyżej.
Poprawa wydajności poprzez usunięcie problemu N+1
Zakładając, że w danej logice potrzebujesz danych z obydwu tabel, to masz następujące sposoby na to, aby uniknąć N+1:
- Jeżeli powiązane encje dla relacji
@ManyToOnelub@OneToOneznajdą się w cache (kontekst persystencji) to dodatkowe zapytania nie zostaną wykonane. Możesz to zrobić np. poprzez wcześniejsze wyszukanie rekordów z drugiej tabeli – osobnequery. Zostanie wykonane osobne zapytanie SQL, a zmapowany wynik zasili cache. - Poprzez dwukierunkowość relacji (dwie strony typu EAGER) i skorzystanie ze złączenia – wyszukujemy nie karty, ale użytkowników, którzy mają karty dla kraju ’
EA'.
Poprawa wydajności – operacje masowe
Korzystanie z automatycznej propagacji aktualizacji zmian w encjach jest wygodne. Nie musisz się przejmować wywoływaniem metody save lub update. Po prostu działa – metoda flush wykryje wszystkie Twoje zmiany i prześle do bazy danych – jedna po drugiej. I istotne jest właśnie to jedna po drugiej.
Wyobraź sobie sytuację ludzi robiących zakupy. Jest kolejka, każdy chce coś kupić, chodzi po sklepie, czeka w kolejce do kasy. Wydaje się to naturalne i prawidłowe. Ale załóżmy, że to Ty chcesz kupić jakiś towar.

I potrzebujesz wielu sztuk.

Nie pójdziesz do sklepu po jedną sztukę, a raczej kupisz od razu kilka. Zaoszczędzisz czas (droga tam i z powrotem, kolejka, płatność).
Podobnie jest z wymianą danych pomiędzy Hibernate a bazą danych. Zapytanie musi zostać wysłane do bazy i skompilowane a zwrócony wynik przetworzony przez Hibernate. Muszą zostać zwolnione zasoby.
Ale zamiast wykonywać te operacje po kolei, można je wykonać masowo. Zaoszczędzisz czas podobnie jak w przypadku zakupów wielu sztuk jaj. Możesz skorzystać z kilku mechanizmów, które zapewnią wykonywanie operacji w grupach:
Update i delete z poziomu JPQL/HQL
Zapytania UPDATE i DELETE dotykające wielu elementów można wykorzystać w przypadku, kiedy masz wspólny mianownik dla encji – na przykład wszystkie karty użytkownika. Przykład: usuwanie wszystkich kart danego użytkownika. Kod Java:
var query = session.createQuery("DELETE FROM Card where cardOwner=:ownerId");
query.setParameter("ownerId", ownerId);
query.executeUpdate();
Należy pamiętać o tym, iż zapytania nie aktualizują encji w cache.
Update i delete z poziomu Criteria API
Wykorzystanie Criteria API dla Hibernate ma zastosowanie podobne jak w punkcie wyżej – także nie aktualizuje encji w cache. Przykład analogiczny jak wyżej, kod Java:
public void deleteUserCardsCriteria(String ownerId) {
//Tworzymy Builder
var criteriaBuilder = session.getCriteriaBuilder();
//CriteriaDelete dla klasy Card
var criteriaDelete = criteriaBuilder.createCriteriaDelete(Card.class);
//Fraza FROM
var delete = criteriaDelete.from(Card.class);
//Fraza Where
criteriaDelete.where(criteriaBuilder.equal(delete.get("cardOwner"), ownerId));
//Wykonanie operacji
session.createQuery(criteriaDelete).executeUpdate();
}
Grupowanie operacji w batch
Grupowanie operacji batch działa inaczej niż z wykorzystaniem QL czy Criteria.
- Korzystasz z API Hibernate w „klasyczny” sposób – zmieniasz wartości pól encji, wykonujesz operacje
persistczydeletedlaSession/EntityManager. - Możesz aktualizować dane encji, usuwać czy dodawać encje w dowolnej kolejności.
- Operacje batch bazują na danych encji znajdujących się w kontekście persystencji (
PersistenceContextczyli cache’u 1-go poziomu). - Operacje zostaną pogrupowane wg typu obiektu i typu operacji (
INSERT/UPDATE/DELETE).
Aby skorzystać z tej właściwości, należy ustawić property hibernate.jdbc.batch_size. Wartość to liczba operacji, po których nastąpi wysyłka zebranych operacji do bazy danych.
Przykład:
- Wyszukujemy w zbiorze kart, te, które należą do danego użytkownika.
- Dla każdej znalezionej karty deaktywujemy ją (atrybut enabled).
- Ustawiamy wartość
hibernate.jdbc.batch_sizena 5.
Wygenerowany log – widać zapytanie SELECT, następnie 5 razy UPDATE i wysłanie polecenia batchowego Executing batch size: 5
[2020-12-16 07:51:05,506] [DEBUG] [o.h.SQL SqlStatementLogger.java:144] select card0_.CARD_ID as card_id1_0_, card0_.COUNTRY as country2_0_, card0_.CARD_OWNER as card_own3_0_, card0_.CARD_UUID as card_uui4_0_, card0_.ENABLED as enabled5_0_ from CARDS card0_ where card0_.ENABLED='Y' limit ?
[2020-12-16 07:51:05,535] [DEBUG] [o.h.SQL SqlStatementLogger.java:144] update CARDS set ENABLED=? where CARD_ID=?
[2020-12-16 07:51:05,537] [DEBUG] [o.h.SQL SqlStatementLogger.java:144] update CARDS set ENABLED=? where CARD_ID=?
[2020-12-16 07:51:05,537] [DEBUG] [o.h.SQL SqlStatementLogger.java:144] update CARDS set ENABLED=? where CARD_ID=?
[2020-12-16 07:51:05,537] [DEBUG] [o.h.SQL SqlStatementLogger.java:144] update CARDS set ENABLED=? where CARD_ID=?
[2020-12-16 07:51:05,537] [DEBUG] [o.h.SQL SqlStatementLogger.java:144] update CARDS set ENABLED=? where CARD_ID=?
[2020-12-16 07:51:05,538] [DEBUG] [o.h.e.j.b.i.BatchingBatch DelegatingBasicLogger.java:384] Executing batch size: 5
Pamiętaj! Ustawienie wartości hibernate.jdbc.batch_size wcale nie oznacza, że operacje zostaną wysłane dokładnie po osiągnięciu ustawionego limitu – może się to stać wcześniej np. przed wywołaniem innego zapytania.
Diagnostyka – śledzenie zapytań SQL
Hibernate podczas wykonywania operacji związanych z komunikacją pomiędzy Java a bazą danych loguje sporo informacji. W zależności od włączonego poziomu logowania w obszarze dotyczącym zapytań SQL zobaczysz między innymi:
- Treść instrukcji SQL.
- Wartości parametrów.
- Informacje o przetwarzaniu wsadowym/batchowym.
Mając wiedzę, jak wygląda wysyłane zapytanie SQL, będziesz w stanie ocenić czy jest ono optymalne.

Oprócz klasycznego logowania Hibernate dostarcza dodatkowego wydruku poleceń SQL, które sterowane jest poprzez properties w Hibernate.
!!! Ale uważaj !!! – włączenie zbyt szerokiego poziomu logowania może spowodować, że wydajność spadnie jeszcze bardziej, a system będzie generował setki MB logów.
Konfiguracja śledzenia SQL poprzez properties Hibernate
W ramach properties znanych Hibernate:
hibernate.show_sql– true/false – wyświetli treść zapytania SQL,hibernate.format_sql– true/false – sformatuje treść wyświetlanego zapytania SQL.
Możesz dodatkowo włączyć kolorowanie składni wyświetlanego SQL
hibernate.highlight_sql– true/false – pokoloruje treść wyświetlanego zapytania SQL w konsoli.
Tak będzie wyglądało wyświetlone i pokolorowane zapytanie
[Hibernate]
select
card0_.CARD_ID as card_id1_0_,
card0_.COUNTRY as country2_0_,
card0_.CARD_OWNER as card_own3_0_,
card0_.CARD_UUID as card_uui4_0_,
card0_.ENABLED as enabled5_0_
from
CARDS card0_
where
card0_.ENABLED='Y' limit ? offset ?
Wartości powyższych properties ustawić można w plikach konfiguracyjnych Hibernate.
Przykład dla hibernate.properties
hibernate.show_sql=true
hibernate.format_sql=true
hibernate.highlight_sql=true
Przykład dla hibernate.cfg.xml
<?xml version = "1.0" encoding = "utf-8"?>
<!DOCTYPE hibernate-configuration SYSTEM
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- -->
<property name="hibernate.show_sql">true</property>
<property name="hibernate.format_sql">true</property>
<property name="hibernate.highlight_sql">true</property>
<!-- -->
</session-factory>
</hibernate-configuration>
Konfiguracja śledzenia SQL poprzez framework do logowania
Aby włączyć śledzenie poleceń SQL w klasycznym logu Hibernate, powinieneś włączyć odpowiedni poziom logowania dla specyficznych klas. Te klasy to:
org.hibernate.SQL- poziom DEBUG
- wyświetla treść zapytania SQL
- przykład logu
[2020-12-15 21:52:39,619] [DEBUG] [o.h.SQL SqlStatementLogger.java:144]
update
CARDS
set
ENABLED=?
where
CARD_ID=?
org.hibernate.type.descriptor.sql.BasicBinder- poziom TRACE
- wyświetla wartości parametrów
- przykład logu
[2020-12-15 21:52:39,618] [TRACE] [o.h.t.d.s.BasicBinder BasicBinder.java:64] binding parameter [1] as [VARCHAR] - [N]
[2020-12-15 21:52:39,618] [TRACE] [o.h.t.d.s.BasicBinder BasicBinder.java:64] binding parameter [2] as [VARCHAR] - [4]
org.hibernate.engine.jdbc.batch.internal.BatchingBatch- poziom DEBUG
- wyświetla informację o tym, że zostały wywołane polecenia wsadowe
- przykład logu
[2020-12-15 21:52:39,621] [DEBUG] [o.h.e.j.b.i.BatchingBatch DelegatingBasicLogger.java:384] Executing batch size: 5
Konfiguracja dla logback – logback.xml
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>[%date] [%level] [%logger{10} %file:%line] %msg%n</pattern>
</encoder>
</appender>
<logger name="org.hibernate.SQL" level="TRACE" additivity="false">
<appender-ref ref="CONSOLE"/>
</logger>
<logger name="org.hibernate.type.descriptor.sql.BasicBinder" level="TRACE" additivity="false">
<appender-ref ref="CONSOLE"/>
</logger>
<logger name="org.hibernate.engine.jdbc.batch.internal.BatchingBatch" level="TRACE" additivity="false">
<appender-ref ref="CONSOLE"/>
</logger>
<root level="info">
<appender-ref ref="CONSOLE"/>
</root>
</configuration>
Konfiguracja logowania w Spring – poprzez application.properties
logging.level.org.hibernate.SQL=TRACE
logging.level.org.hibernate.type.descriptor.sql.BasicBinder=TRACE
Poprawa wydajności – pobieraj tylko to czego potrzebujesz
Logika aplikacji operująca na danych z określonych tabel może być różna, w zależności od funkcjonalności aplikacji.
- Czasami nie potrzebujesz dociągać wszystkich powiązanych obiektów, żeby dowiedzieć się, że istnieją powiązane dane. Przykład chcesz wyświetlić listę z danymi użytkowników i informacją o liczbie kart. Nie musisz pobierać listy kart, aby tylko pobrać rozmiar.
- Możesz wykorzystać pole wyliczalne w klasie – anotacja
@Formula. Przykład dla tabeliUSERS, encjaUser.
- Możesz wykorzystać pole wyliczalne w klasie – anotacja
@Formula("(SELECT COUNT(1) FROM CARDS C WHERE C.CARD_OWNER_ID=USER_ID)")
private int cardsCount;
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
- Możesz skorzystać z projekcji. Projekcje to różne zachowanie i wygląd danych dla tej samej tabeli. Hibernate na to pozwala – możesz zdefiniować wiele encji na tej samej tabeli i mieć inny zbiór pól dla wyszukiwania, a inny dla wejścia w szczegóły. Ale zaleca się, aby modyfikacje i dodawanie były jedynie tam, gdzie masz dostęp do szczegółów. Możesz zabezpieczyć się przed przypadkową modyfikacją, na przykład poprzez:
- Użycie anotacji
org.hibernate.annotations.Immutable. - Usunięcie/ukrycie (private) metod typu set dla pól encji oraz zezwolenie jedynie na operacje wyszukiwania z poziomu
DAO/Repository. - Dodaj metodę rzucającą wyjątek, którą oznacz anotacjami
@PrePersist, @PreUpdate, @PreRemove. W ten sposób dodatkowo się zabezpieczysz przed zmianami.
- Użycie anotacji
- Widoki bazodanowe (
CREATE VIEW AS SELECT) to nazwana definicja jakiegoś zapytania typuSELECT. Hibernate umożliwia stworzenie encji opartej o widok. Oznaczenie encji dla widoku nie różni się to niczym od encji dla tabeli. - Anotacja @EntityGraph umożliwia własne sterowanie doczytywaniem dla relacji
@Entity
@Table(name = "CARDS")
@Data
@AllArgsConstructor
@NoArgsConstructor
@NamedEntityGraphs({
@NamedEntityGraph(name = "softwareskill-no-relations",
attributeNodes = {
@NamedAttributeNode("cardId"),
@NamedAttributeNode("cardUuid"),
@NamedAttributeNode("cardCountry")
}
),
@NamedEntityGraph(name = "softwareskill-all-relations",
attributeNodes = {
@NamedAttributeNode("cardId"),
@NamedAttributeNode("cardUuid"),
@NamedAttributeNode("cardCountry"),
@NamedAttributeNode("cardOwner")
}
)
})
public class CardByEntityGraph {
@Id
@Column(name = "CARD_ID")
private String cardId;
@Column(name = "CARD_UUID")
private String cardUuid;
@Column(name = "COUNTRY")
@Enumerated(EnumType.STRING)
private CardCountry cardCountry;
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "CARD_OWNER_ID")
private UserUnidirectional cardOwner;
}
W powyższym przykładzie masz zdefiniowane dwa rodzaje grafów dociągania danych:
softwareskill-no-relations– bez dociągania danych o relacjach (nawet jeśli jest EAGER nad polem). Przykład wywołania poniżej
public Optional<CardByEntityGraph> findByIdNoRelations(String cardId) {
var entityGraph = session.getEntityGraph("softwareskill-no-relations");
Map<String, Object> properties = new HashMap<>();
properties.put("javax.persistence.fetchgraph", entityGraph);
var value = session.find(CardByEntityGraph.class, cardId, properties);
return Optional.ofNullable(value);
}
softwareskill-all-relations– z dociągnięciem relacji
Wpis który czytasz to zaledwie fragment wiedzy zawartej w Programie szkoleniowym Java Developera od SoftwareSkill. Mamy do przekazania sporo usystematyzowanej wiedzy z zakresu kluczowych kompetencji i umiejętności Java Developera. Program składa się z kilku modułów w cotygodniowych dawkach wiedzy w formie video.
Wydajność Hibernate
Twórz szybko działające aplikacje z wydajną i zoptymalizowaną obsługą bazy danych.
Podsumowanie
Rozwiązanie jest zależne od potrzeb danej sytuacji. Zależy, z czym się mierzysz i co może być problemem. Ile jest tabel, jakiego rodzaju są kolumny (np. bardzo duże), jaka jest ich liczba. Przedstawiłem Ci kilka aspektów dotyczących problemów z wydajnością i pokazałem, w jaki sposób możesz rozwiązać dany problem. Ale najważniejsze jest to, abyś wiedział jak zachowuje się framework Hibernate i potrafił diagnozować i śledzić wymianę danych z bazą.
Gdybyś potrzebował jeszcze więcej:
Jesteś Java Developerem?
Przejdź na wyższy poziom wiedzy
„Droga do Seniora” 🔥💪
Jesteś Team Leaderem? Masz zespół?
Podnieś efektywność i wiedzę swojego zespołu 👌
Linki
- https://vladmihalcea.com/n-plus-1-query-problem/
- https://www.baeldung.com/hibernate-logging-levels
- https://thorben-janssen.com/hibernate-logging-guide/
- https://docs.jboss.org/hibernate/orm/5.4/userguide/html_single/Hibernate_User_Guide.html#configurations-logging
Obrazy:
