W jednym z ostatnich artykułów Schema Registry w Apache Kafka opisałem czym jest i do czego służy Schema Registry. Zapraszam do przeczytania, jeśli temat Schemy Registry i Avro jest Ci obcy. Ten wpis jest kontynuacją poprzedniego, gdzie skupimy się na części praktycznej. W tym wpisie dowiesz się o:
- Jak uruchomić Confluent Schema Registry na Docker
- Napiszemy producenta oraz konsumenta wiadomości w Spring Boot z wykorzystaniem Apache Kafka, Avro oraz rejestru schematów Confluent Schema Registry
Na pierwszy ogień idziemy z plikiem docker-compose.yml, w którym zdefiniujemy kolejno serwisy:
- zookeeper
- broker
- kafka-tools
- schema-registry
- control-center
version: "3"
services:
zookeeper:
image: confluentinc/cp-zookeeper:5.4.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
restart: unless-stopped
broker:
image: confluentinc/cp-server:5.4.0
hostname: broker
container_name: broker
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker:29092
CONFLUENT_METRICS_REPORTER_ZOOKEEPER_CONNECT: zookeeper:2181
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1
CONFLUENT_METRICS_ENABLE: "true"
CONFLUENT_SUPPORT_CUSTOMER_ID: "anonymous"
restart: unless-stopped
kafka-tools:
image: confluentinc/cp-kafka:5.4.0
hostname: kafka-tools
container_name: kafka-tools
command: ["tail", "-f", "/dev/null"]
network_mode: "host"
restart: unless-stopped
schema-registry:
image: confluentinc/cp-schema-registry:5.4.0
hostname: schema-registry
container_name: schema-registry
depends_on:
- zookeeper
- broker
ports:
- "8081:8081"
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL: "zookeeper:2181"
restart: unless-stopped
control-center:
image: confluentinc/cp-enterprise-control-center:5.4.0
hostname: control-center
container_name: control-center
depends_on:
- zookeeper
- broker
- schema-registry
ports:
- "9021:9021"
environment:
CONTROL_CENTER_BOOTSTRAP_SERVERS: 'broker:29092'
CONTROL_CENTER_ZOOKEEPER_CONNECT: 'zookeeper:2181'
CONTROL_CENTER_SCHEMA_REGISTRY_URL: "http://schema-registry:8081"
CONTROL_CENTER_REPLICATION_FACTOR: 1
CONTROL_CENTER_INTERNAL_TOPICS_PARTITIONS: 1
CONTROL_CENTER_MONITORING_INTERCEPTOR_TOPIC_PARTITIONS: 1
CONFLUENT_METRICS_TOPIC_REPLICATION: 1
PORT: 9021
restart: unless-stopped
Po wykonaniu komendy docker-compose up -d, Docker pobierze obrazy, utworzy i uruchomi kontenery. Jeśli używasz Docker for Windows, powinieneś/aś zobaczyć coś podobnego jak na obrazie poniżej.
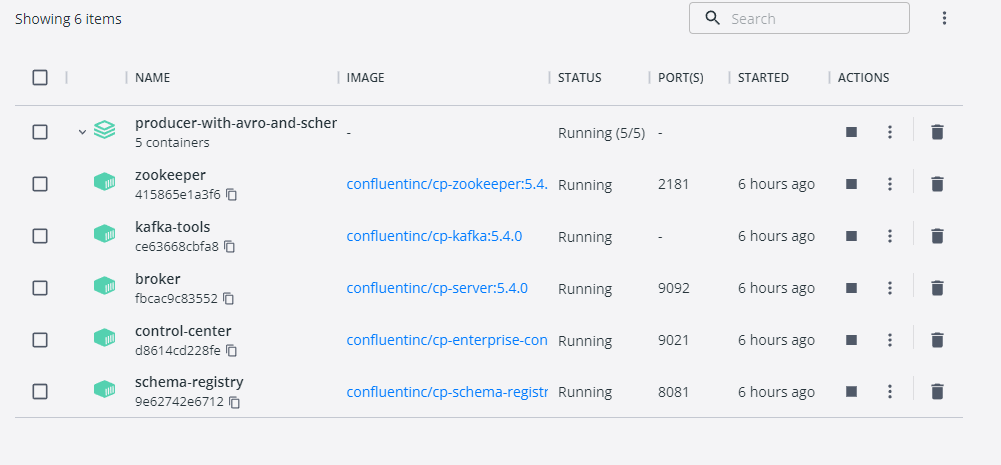
Świetnie! Właśnie uruchomiłeś klaster Apache Kafka ze Schemą Regitry oraz panelem kontrolnym klastra od Confluent! Otwórz teraz w przeglądarce stronę: http://localhost:9021. Twoim oczom powinna ukazać się następująca strona:
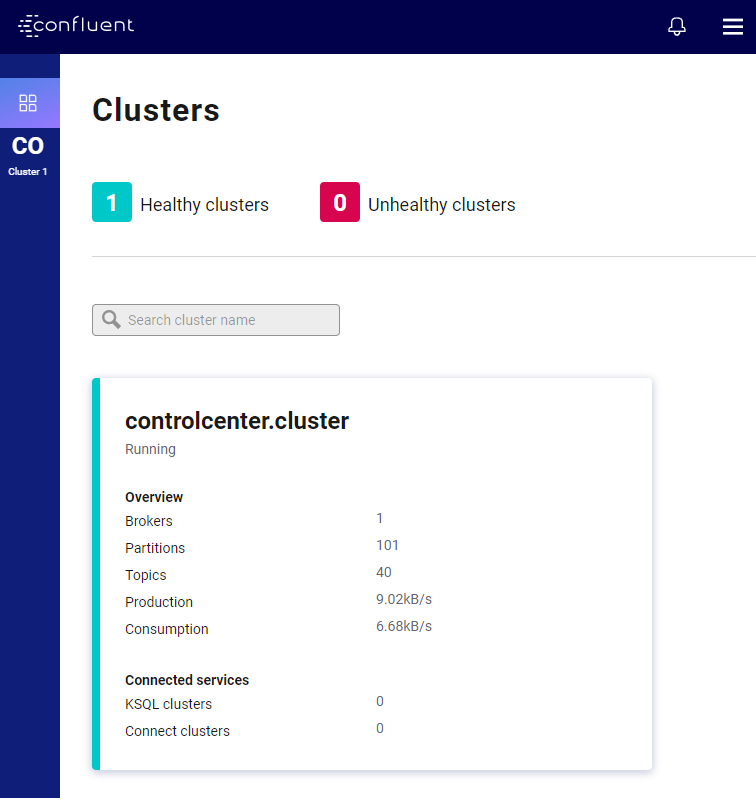
Mamy tutaj panel kontrolny całego klastra Apache Kafka. Panel ten jest serwowany przez Confluent, który jest Rolls-Royce w świecie Kafki. W panelu tym, możesz zarządzać całym klastrem. Możesz tworzyć topiki, wgrywać schematy avro, podglądać co się dzieje na kolejkach w real time! i wiele wiele innych – po prostu poklikaj po GUI.
Lecąc dalej za ciosem stwórzmy topic na klastrze Kafki, do którego będziemy wysyłać eventy. Możemy to zrobić z poziomu konsoli, podpinając się pod terminal dockera i wklejając polecenie:
kafka-topics --zookeeper zookeeper:2181 --create --topic orders --partitions 1 --replication-factor 1
Dokładnie tak jak na obrazie poniżej:
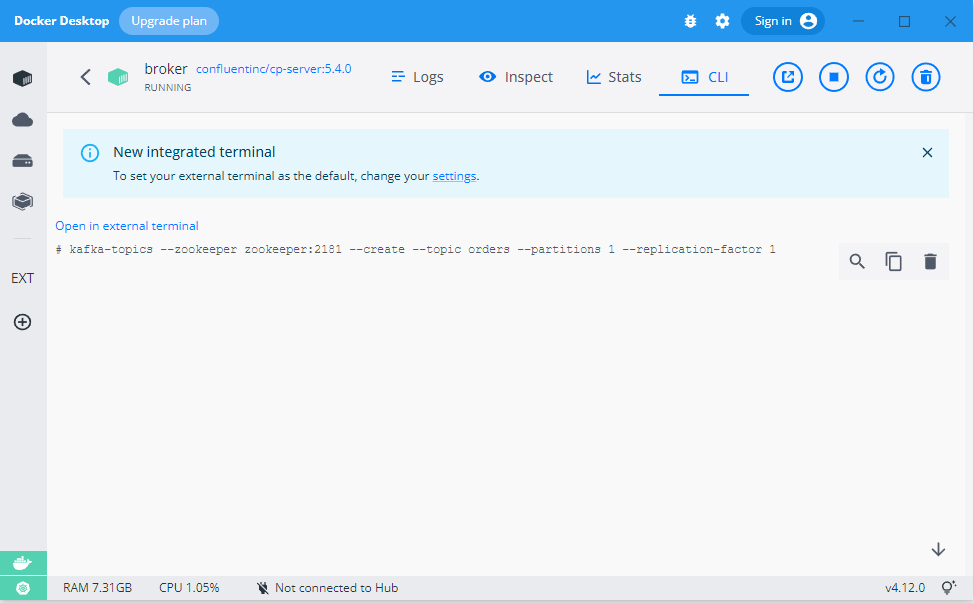
Polecenie to utworzy topic o nazwie „orders”. Topic będzie posiadał jedną partycję oraz jedną replikę. Drugą możliwością jest „wyklikanie” topica wprost z GUI Confluenta. Tę opcję będę polecał – bo nie musisz znać dokładnej składni polecenia. Wszystko możesz wyklikać, a opcji jest naprawdę sporo.
Jak widzimy na poniższym zdjęciu, opcji do wyklikania jest sporo. Możemy zdefiniować m.in. liczbę partycji czy manualnie ustawić ilość replik (parametr replication-factor) oraz wskazać Kafce ile minimalnie replik musi się zsynchronizaować, zanim zostanie odesłane potwierdzenie ACK do producenta (parametr min.insync.replicas). Możemy również ustawić politykę czyszczenia danych. Jest to bardzo wygodne, a przynajmniej wygodniejsze niż wpisywanie wszystkich parametrów „z palca” w konsoli.
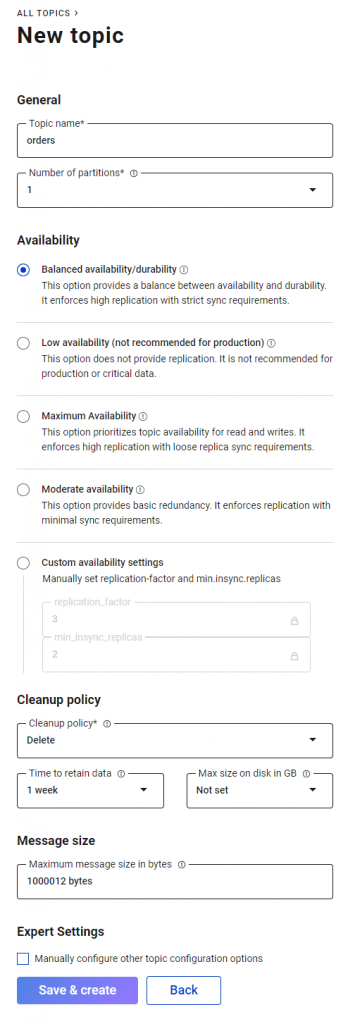
Więcej o tych parametrach mówię w naszym Programie Java Developera.
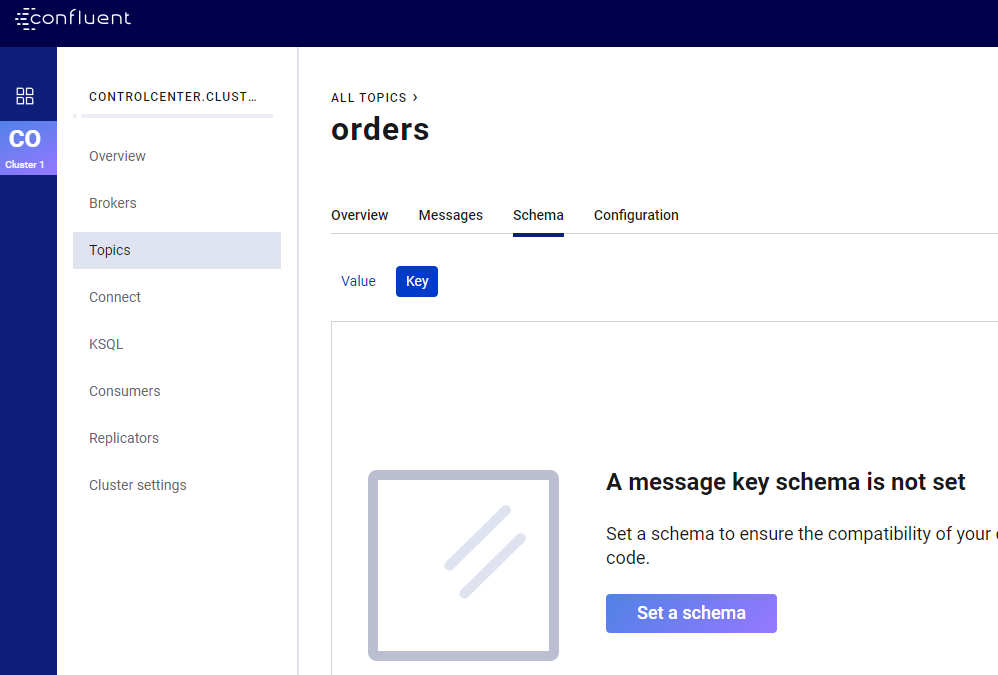
Kiedy mamy już działający klaster oraz zdefiniowany topic, przejdźmy do następnego kroku i wgrajmy schemat Avro. Jak wiadomo, komunikaty na Apache Kafka składają się z klucza oraz wartości. Klucz to identyfikator biznesowy naszej wiadomości, np. userId, orderId itp.. Dzięki podaniu klucza wiadomości, te z tym samym kluczem lądują na tej samej fizycznej partycji (jest to jeden z elementów zapewniających prawidłową kolejność odczytu). Wiadomo też, że sama Kafka nie dba o typ danych, które są wysyłane. Dla Kafki liczą się tylko bajty. Musimy więc zdefiniować sposób deserializacji klucza oraz wiadomości. Jako klucza użyjemy zwykłego Stringa, a jako wartość wiadomości – Avro. Dla tego przechodzimy do zakładki „Schema” oraz do podzakładki „Key”.
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
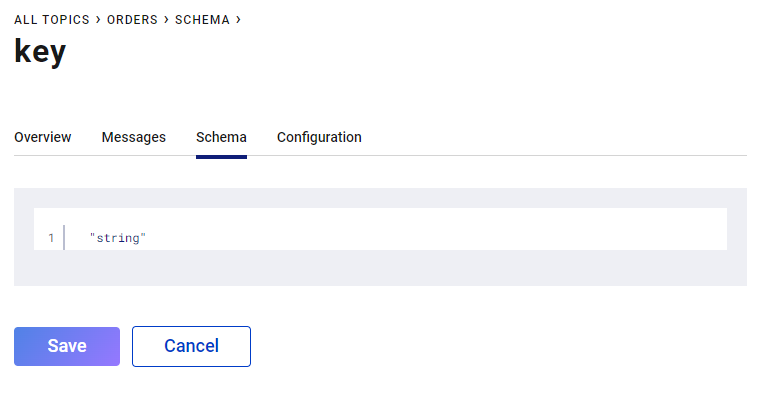
Następnie wpisujemy „string”, tak jak na zdjęciu poniżej:
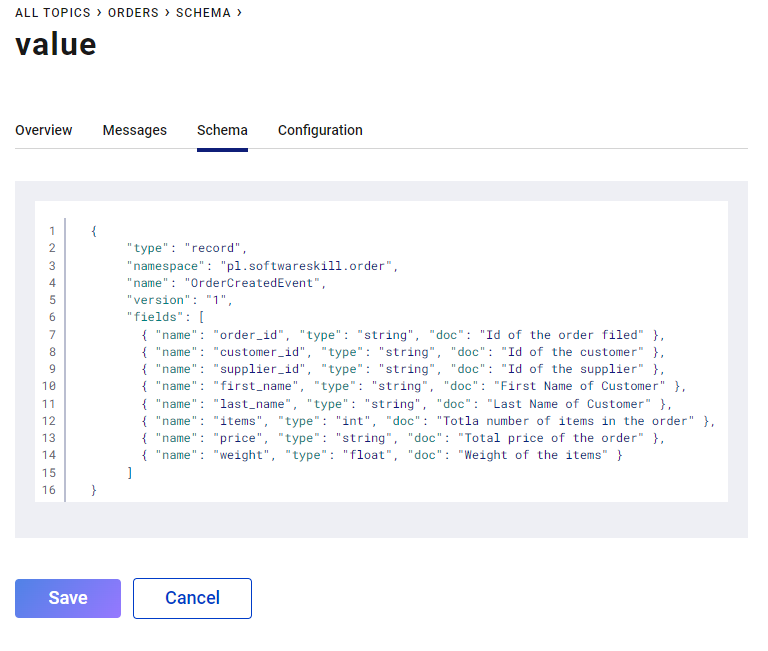
Przechodzimy do podzakładki „Value” i pole textarea wpisujemy schemat Avro, dokładnie jak na zdjęciu poniżej:
Super! Mamy już postawiony klaster Kafki ze Schema Registry, zdefiniowany topic oraz schemę Avro, służącą do serializacji i deserializacji komunikatów, które będziemy wysyłać i odbierać z klastra. W sprawie wgrywania schematów Avro chciałbym dodać co oferuje Confluent Schema Registry. Otóż możemy zdefiniować formę kompatybilności (lub jej brak) przy wgrywaniu kolejnych wersji tego samego schematu. Zabezpieczy to nas przed „pigułką śmierci”, czyli efekcie, w którym konsument zawiesza się na ciągłym procesowaniu deserializacji tego samego komunikatu (więcej o tym temacie mówię w Programie Java Developera).
Opcje kompatybilności widzisz na poniższym obrazie:
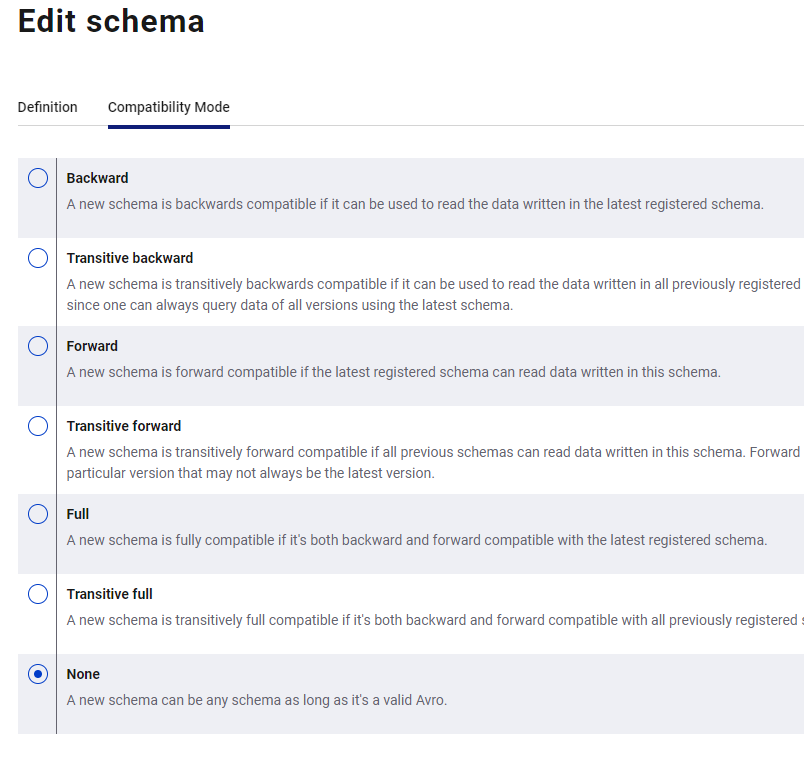
Dla testu usuńmy jakąkolwiek kompatybilność wybierając radio-button na „None” (nie rób tego na produkcji!). Następnie wgrajmy nowy schemat:
{
"type": "record",
"namespace": "pl.softwareskill.order",
"name": "OrderCreatedEvent",
"version": "2",
"fields": [
{ "name": "order_id", "type": "string", "doc": "Id of the order filed" }
]
}
Przejdźmy teraz do kodu. Zaczniemy od producenta wiadomości i od definicji pliku pom:
Apache Kafka – wydajność vs. gwarancja dostarczenia wiadomości
Jak stworzyć piekielnie szybką albo maksymalnie bezpieczną wersję producenta oraz konsumenta.

<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.5</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>pl.softwareskill.kafka.producer</groupId>
<artifactId>producer-with-avro-and-schema-registry</artifactId>
<version>1.0-SNAPSHOT</version>
<name>producer</name>
<description>Demo project for Apache Kafka producer in Spring Boot</description>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-schema-registry-client</artifactId>
<version>5.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.11.1</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-avro-serializer</artifactId>
<version>5.2.1</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-streams-avro-serde</artifactId>
<version>5.3.0</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<repositories>
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>11</source>
<target>11</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.11.1</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<sourceDirectory>${project.basedir}/src/main/resources/</sourceDirectory>
<outputDirectory>${project.build.directory}/generated-sources/java/</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Rzeczą wartą wyjaśnienia jest plugin avro-maven-plugin. Skanuje on katalog zdefiniowany w sourceDirectory, pobiera z niego pliki ze schematami Avro (pliki *.avsc), a następnie generuje z nich klasy Java do katalogu outputDirectory.
Poniżej prezentuje plik application.yml
spring:
kafka:
topic:
orders: orders
producer:
bootstrap-servers: localhost:9092
schema:
registry:
url: http://localhost:8081
Jak widzisz, definiujemy tutaj listę bootstrap-servers, służącą do połączenia się z klastrem, nazwę topicu oraz adres schemy registry. Konfiguracja propertek może wyglądać następująco:
@FieldDefaults(level = PRIVATE)
@Configuration
@Getter
@Setter
public class KafkaProperties {
@Value("${spring.kafka.producer.bootstrap-servers}")
String bootstrapServers;
@Value("${spring.kafka.topic.orders}")
String topicName;
@Value("${spring.kafka.producer.schema.registry.url}")
String schemaRegistryUrl;
}
Przejdźmy do konfiguracji producenta:
@EnableKafka
@Configuration
@RequiredArgsConstructor
@FieldDefaults(level = PRIVATE, makeFinal = true)
class KafkaProducerConfiguration {
static final String SCHEMA_REGISTRY_URL_KEY = "schema.registry.url";
KafkaProperties kafkaProperties;
@Bean("kafkaTemplate")
public KafkaTemplate<String, SpecificRecord> kafkaTemplate(final ProducerFactory<String, SpecificRecord> producerFactory) {
return new KafkaTemplate<>(producerFactory);
}
@Bean
public ProducerFactory<String, SpecificRecord> producerFactory() {
final var producerConfig = getProducerConfig();
return new DefaultKafkaProducerFactory<>(producerConfig);
}
private Map<String, Object> getProducerConfig() {
final Map<String, Object> properties = new HashMap<>();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaProperties.getBootstrapServers());
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class);
properties.put(ProducerConfig.RETRIES_CONFIG, 1);
properties.put(ProducerConfig.RECONNECT_BACKOFF_MS_CONFIG, "5000");
properties.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, "5000");
properties.put(SCHEMA_REGISTRY_URL_KEY, kafkaProperties.getSchemaRegistryUrl());
return properties;
}
}
Rozwiązaniem, o którym warto wspomnieć więcej jest klasa serializacji KafkaAvroSerializer.class dostarczona przez Confluent. Otóż dzięki temu serializatorowi, obsługa schemy registry jest dla nas totalnie przeźroczysta. Wystarczy, że wstrzykniemy propertkę „schema.registry.url” przy definicji naszego producenta a serializator od Confluenta wykona resztę „brudnej roboty” związanej z dodawaniem do wysyłanego komunikatu id schemy.
Następnie używamy wcześniej zdefiniowanego KafkaTemplate, aby wysłać wiadomość:
@Slf4j
@Service
@RequiredArgsConstructor
@FieldDefaults(level = PRIVATE, makeFinal = true)
public class KafkaSyncMessagePublisher implements MessagePublisher<SpecificRecord> {
KafkaTemplate kafkaTemplate;
@Override
public void publish(final String topicName, final SpecificRecord message, final String key) {
final var producerRecord = new ProducerRecord<>(topicName, key, message);
try {
final var sendResult = kafkaTemplate.send(producerRecord);
kafkaTemplate.flush();
sendResult.get();
log.info("Send message");
} catch (final InterruptedException e) {
Thread.currentThread().interrupt();
log.error("Sending interrupted", e);
} catch (final KafkaException | ExecutionException e) {
log.error("There was error while synchronous send event to Kafka cluster", e);
}
}
}
Świetnie! Mamy już działającego producenta wiadomości. Przejdźmy więc do aplikacji konsumenta wiadomości. Plik pom będzie wyglądał podobnie:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.5</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>pl.softwareskill.kafka.consumer</groupId>
<artifactId>consumer-with-avro-and-schema-registry</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-schema-registry-client</artifactId>
<version>5.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.11.1</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-avro-serializer</artifactId>
<version>5.2.1</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-streams-avro-serde</artifactId>
<version>5.3.0</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<repositories>
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>11</source>
<target>11</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.11.1</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<sourceDirectory>${project.basedir}/src/main/resources/</sourceDirectory>
<outputDirectory>${project.build.directory}/generated-sources/java/</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Poniżej plik application.yml
spring:
kafka:
topic:
orders: orders
consumer:
bootstrap-servers: localhost:9092
schema:
registry:
url: http://localhost:8081
Wstrzykujemy dwie propertki do klasy KafkaProperties
@FieldDefaults(level = PRIVATE)
@Configuration
@Getter
@Setter
class KafkaProperties {
@Value("${spring.kafka.consumer.bootstrap-servers}")
String bootstrapServers;
@Value("${spring.kafka.consumer.schema.registry.url}")
String schemaRegistryUrl;
}
A tutaj mamy konfigurację konsumenta Apache Kafka.
@Slf4j
@EnableKafka
@Configuration
@RequiredArgsConstructor
@FieldDefaults(level = PRIVATE, makeFinal = true)
class KafkaConsumerConfiguration {
static final String SCHEMA_REGISTRY_URL_KEY = "schema.registry.url";
KafkaProperties kafkaProperties;
@Bean(OrderCreatedConst.Listeners.MESSAGE_READ_LISTENER_CONTAINER_FACTORY)
public ConcurrentKafkaListenerContainerFactory<String, OrderCreatedEvent> kafkaListenerContainerFactory() {
var factory = new ConcurrentKafkaListenerContainerFactory<String, OrderCreatedEvent>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
@Bean
public ConsumerFactory<String, OrderCreatedEvent> consumerFactory() {
final var consumerConfig = getConsumerConfig();
return new DefaultKafkaConsumerFactory<>(consumerConfig);
}
private Map<String, Object> getConsumerConfig() {
final Map<String, Object> properties = new HashMap<>();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaProperties.getBootstrapServers());
properties.put(ConsumerConfig.RECONNECT_BACKOFF_MS_CONFIG, "5000");
properties.put(ConsumerConfig.RETRY_BACKOFF_MS_CONFIG, "5000");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, KafkaAvroDeserializer.class);
properties.put(SCHEMA_REGISTRY_URL_KEY, kafkaProperties.getSchemaRegistryUrl());
properties.put(KafkaAvroDeserializerConfig.SPECIFIC_AVRO_READER_CONFIG, "true");
return properties;
}
}
Podobnie jak w producencie, w tym przypadku musimy podać klasy deserializatora klucza i wartości wiadomości. Klucz do String więc użyjemy StringDeserializer.class, natomiast wartość wiadomości to bajty zserializowane za pomocą Avro. Tutaj użyjemy deserializatora dostarczonego przez Confluent – KafaAvroDeserializer.class, dzięki temu obsługa Schema Registry jest dla nas przeźroczysta (zobaczysz to w późniejszym debagu odczytu wiadomości).
Poniżej widzisz kod listenera wiadomości.
@Slf4j
@RequiredArgsConstructor
@FieldDefaults(level = PRIVATE, makeFinal = true)
@Component
class MessageListener {
private OrderCreatedFacade orderCreatedFacade;
@KafkaListener(topics = "orders", groupId = "group-1", containerFactory = MESSAGE_READ_LISTENER_CONTAINER_FACTORY)
public void handleMessage(OrderCreatedEvent event) {
log.info("[READ MESSAGE] message {}", event.toString());
orderCreatedFacade.consume(event);
}
}
Dzięki użyciu KafkaAvroDeserializera, dostarczonego przez Confluent, mamy zapewnioną obsługę Schema Registry. Na poniższym zdjęciu widać wejście w proces deserializacji po odebraniu komunikatu z klastra, ale przed dostarczeniem zdeserializowanego komunikatu do listenera w kodzie. Jak widzisz z payloda komunikatu jest wyłuskiwany id schemy, a następnie jest robiony strzał po RestAPI do Schemy Registry po samą schemę. Kiedy otrzymamy schemę, przystępujemy do deserializacji, a następnie uzupełniony kontenerek z danymi (wygenerowana na podstawie schematu, klasa Java) jest przekazywana do listenera.
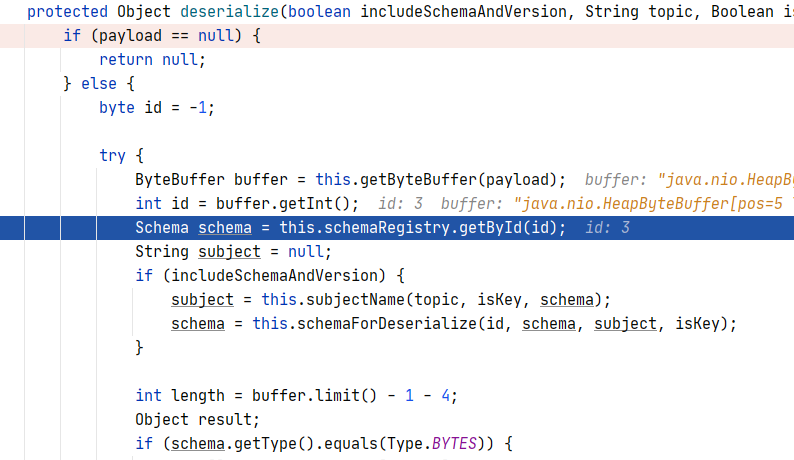
Super! Mamy już praktycznie wszystko. Udało nam się postawić klaster Kafki oraz Schemę Registry na Docker. Utowrzyliśmy topic, wgraliśmy schemę. Stworzyliśmy producenta oraz konsumenta. Zachęcam Ciebie do poklikania po GUI klastra Kafki, jest tam wiele ciekawych opcji, jak np. monitorowanie kolejki (zdjęcie poniżej).
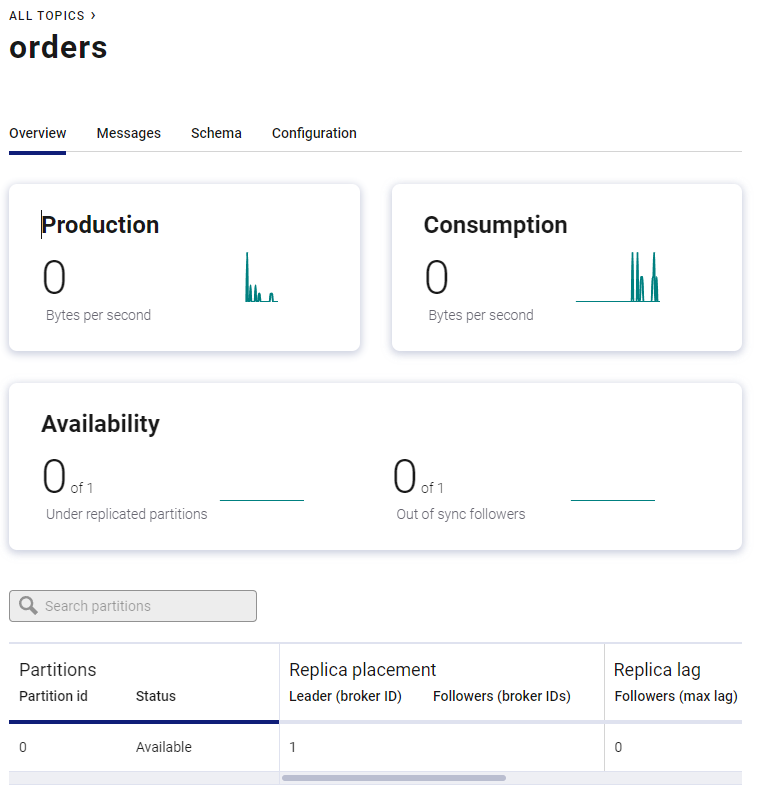
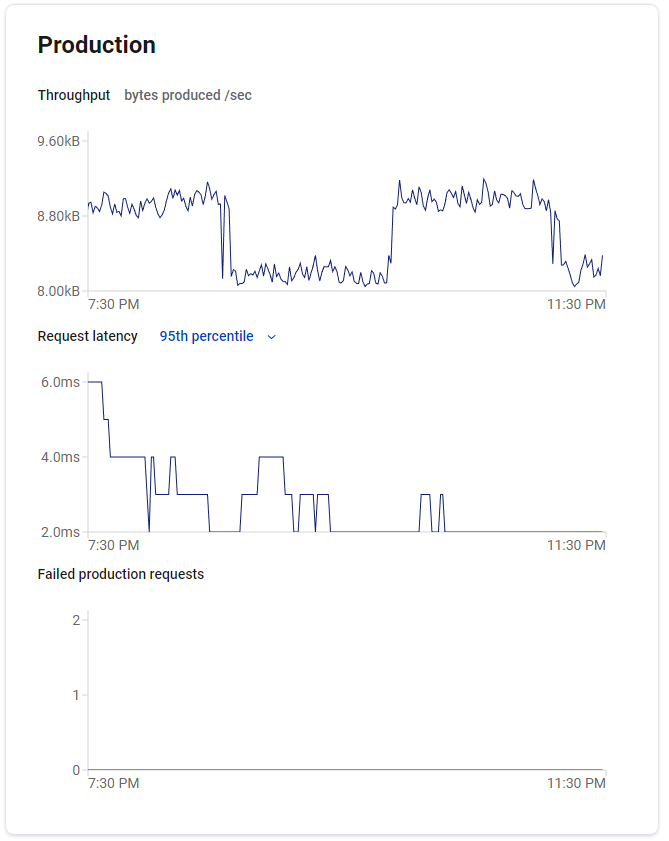
Gdybyś potrzebował jeszcze więcej:
Jesteś Java Developerem?
Przejdź na wyższy poziom wiedzy
„Droga do Seniora” 🔥💪
Jesteś Team Leaderem? Masz zespół?
Podnieś efektywność i wiedzę swojego zespołu 👌
Podoba Ci się ten artykuł? Weź więcej.
Jeżeli uważasz ten materiał za wartościowy i chcesz więcej treści tego typu – nie przegap ich i otrzymuj je prosto na swoją skrzynkę. Nawiążmy kontakt.
