Tym artykułem rozpoczynamy kolejną serię – kolejki wiadomości. Dzisiejszym tematem będzie Apache Kafka. Na wstępie omówimy czym są i do czego są nam w ogóle potrzebne systemy kolejkowe. W końcu zajmiemy się tytułowym bohaterem i omówimy architekturę oraz sposób działania kolejki Apache Kafka.
Do czego służą systemy kolejkowe?
Wyobraźmy sobie, że nasz system składa się z kilku aplikacji. Dla przykładu niech będą to trzy aplikacje frontendowe i jedna aplikacja służąca do zbierania metryk z tych pozostałych. Schemat blokowy może wyglądać następująco.

Powiedzmy teraz, że frontowe usługi prezentują dane klientowi, ale oprócz tego produkują dane np.
- średni czas wykonania zapytań,
- feedbacki do marketingu (co klient robił na stronie),
- ilość błędnych logowań.
Ktoś wpada na pomysł, że warto jest zbierać takie metryki w bazie danych, aby móc je później analizować. Następnie pojawia się pomysł, aby zbierać dodatkowe metryki z innych aplikacji. Nagle, wraz z rozwojem systemu, aplikacji produkujących metryki, jak i samych metryk pojawia się coraz więcej. Schemat blokowy, uwzględniający większą liczbę aplikacji i metryk może wyglądać następująco.

Jak widzisz na powyższym schemacie, bezpośrednia komunikacja pomiędzy mikrousługami jest bardzo skomplikowana. Po pewnym czasie, kiedy aplikacji i różnych typów komunikatów przybędzie, system jest bardzo skomplikowany w utrzymaniu, dlatego, że aplikacje bezpośrednio integrują się ze sobą nawzajem. Koszt wdrożenia kolejnego typu komunikatu, czy aplikacji, dalej komplikuje system.
Model Publish-Subscribe
W miejsce bezpośrednich integracji, tworzących powoli pajęczynę, można wprowadzić pośrednika. Wszyscy, którzy chcą tworzyć nowe komunikaty, komunikują się z pośrednikiem, posiadając jeden punkt integracji. Z kolei wszyscy, którzy chcą odczytywać komunikaty, subskrybują komunikaty pośrednika.
Analogię można porównać do serwisów społecznościowych. Twórca publikuje treści, a zainteresowani odbiorcy (subskrybenci) odbierają treści, po ich opublikowaniu (lub w swoim wolnym czasie), jeżeli są nimi zainteresowani. Serwis społecznościowy pełni tu rolę pośrednika, wyręczając twórcę od „ręcznego” powiadomienia tysięcy zainteresowanych.
Pośrednik ten w systemach kolejkowych nazywa się Brokerem. Nowy schemat blokowy uwzględniający brokera może wyglądać następująco.
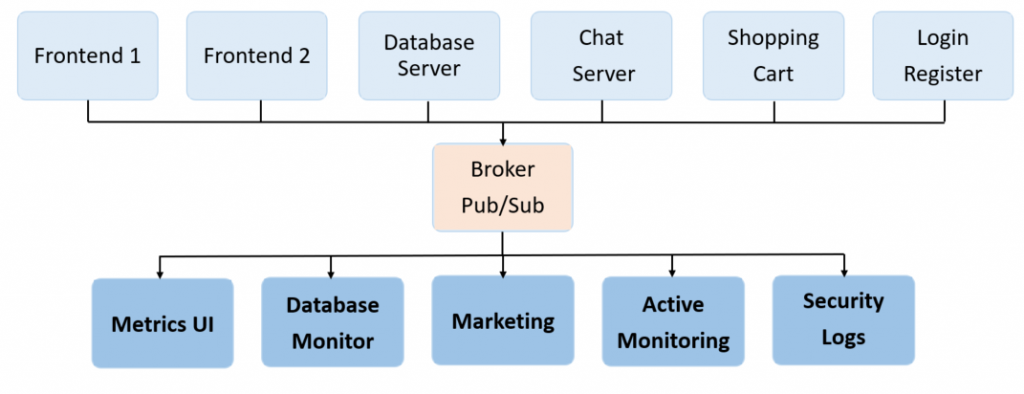
Aplikacje takie jak Frontend 1 czy Shopping Cart w systemach kolejkowych nazywamy Producentami wiadomości natomiast aplikacje takie jak Metrics UI czy Security Logs nazywamy Konsumerami wiadomości. Pomiędzy nimi znajduje się część wymiany komunikatów na brokerze, jakim jest Topic. Jest to nazwany kanał komunikacji segregujący wiadomości.
Producenci publikują wiadomości do wcześniej zdefiniowanego Topica, konsumenci zaś nasłuchują (subskrybują) konkretny Topic.
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
Jeśli konsument zasubskrybuje się w konkretnym topicu – będzie dostawał informację, kiedy jakaś wiadomość się na nim pojawi (zupełnie jak przy analogii do serwisów społecznościowych). W ten sposób separujemy tych, którzy produkują wiadomości od tych, którzy je konsumują. Producent nie musi wiedzieć o istnieniu konsumenta oraz kim jest. Pojawia się spore uproszczenie w integrowaniu kolejnych aplikacji. Przy dodaniu kolejnego typu wiadomości czy kolejnej usługi produkującej / konsumującej koszt wdrożenia jest dużo niższy (w porównaniu do pajęczyny połączeń z poprzedniego przykładu).
Przypadki użycia systemów kolejkowych
Metryki to oczywiście niejedyny przykład użycia komunikacji za pomocą kolejek. Poniżej wy-listowałem najpopularniejsze przypadki użycia systemów kolejkowych.
- Asynchroniczna komunikacja pomiędzy mikrousługami – np. jedna mikrousługa produkuje dane, które odczytuje inna mikrousługa.
- Informowanie o zmianach – np. aktualizacja cache po zmianach danych – subskrybowanie zmian. Kolejnym przykładem może być aplikacja giełdowa. Bez sensu jest odpytywać serwer co kilka ms o aktualny kurs waluty. Lepiej jest za-subskrybować się na topicu informującym o zmianach wartości danej pary walutowej.
- Przesuwanie ciężkich zadań w tło – np. rozsyłka maili, czy zapis danych statystycznych (nie ma sensu robić tego synchronicznie i czekać na odpowiedź. Zlećmy to jakiemuś podsystemowi – niech pobierze daną z szyny i niech wykona pracę w tle, w swoim wolnym czasie)
- Inernet Of Things (IoT) – czyli urządzenia komunikujące się przez internet, np. sensor smogu, temperatury mogą co jakiś czas wrzucać na kolejkę informacje o aktualnym stanie pomiarów, a system subskrybujący (konsumer) może na podstawie tych danych rysować wykresy temperatury w czasie czy powiadamiać o aktualnej jakości powietrza na danym obszarze. Kolejnym przykładem może być monitoring GPS pojazdów – co jakiś czas urządzenie wysyła na kolejkę informacje o aktualnej pozycji GPS.
Jak więc widzisz, drogi czytelniku – systemy kolejkowe mają niesamowity potencjał i występują w większości projektów, z którymi będziesz (lub masz:)) doczynienia.
Kolejki można wytłumaczyć na dwa główne sposoby. Pierwszy z nich to przedstawienie faktów i stopniowe tłumaczenie jak to działa. My natomiast wybierzemy ten drugi sposób – czyli spróbujemy „wymodelować” kolejkę, która spełni nasze oczekiwania. Przejdźmy więc do założeń, jakie musi spełniać nasz system kolejkowy.
Założenia systemu kolejkowego
Nasze kolejki na pewno muszą być:
- szybkie
- bezpieczne
- bezawaryjne
- muszą posiadać proste API
- możliwie najprostszą konfigurację
Na poniższym schemacie przedstawiłem schemat blokowy uproszczonego systemu kolejkowego, składającego się z producenta, konsumenta i tajemniczego bloku X, który będzie naszym systemem kolejkowym.
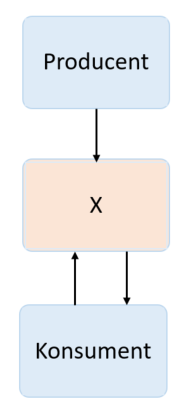
Kiedy producent wyprodukuje jakieś wiadomości, to zanim konsumer je odczyta – musimy je gdzieś przechować. Jakieś pomysły? Może baza danych? Wówczas w naszym tajemniczym bloku X pojawiłaby się baza, do której dane zapisywaliby producenci. Natomiast konsumenci robiliby zapytanie o ostatni rekord, który nie został jeszcze odczytany. Czy to dobre rozwiązanie? Cóż, bazy danych zostały zaprojektowane nie tylko do zapisywania i odczytywania danych, ale także do wyszukiwania i robienia skomplikowanych zapytań. Natomiast systemy kolejkowe, z założenia nie służą do wyszukiwania czy do aktualizacji danych tylko do ich kolejkowania. Dodatkowy problem przy zastosowaniu bazy danych to „puchnące dane”. Kolejka nie może w nieskończony czas trzymać danych, bo szybko skończyłoby się na nie miejsce.
Partycja
To, co nas interesuje to możliwość dokładania danych na końcu, bez ich aktualizowania. Konsument natomiast odczytuje ostatnie dane, których jeszcze nie przeczytał. Logi aplikacji. To jest to! Aplikacja produkuje logi, odkłada je w pliku. A my możemy się „za-subskrybować” do konkretnego loga i patrzeć co nowego się w nim pojawiło. Zapis do pliku na ostatniej pozycji oraz odczyt pozycji to bardzo szybkie operacje. Nie ma również problemu, żeby dołożyć kolejnego konsumenta czy producenta. O to nam chodziło!
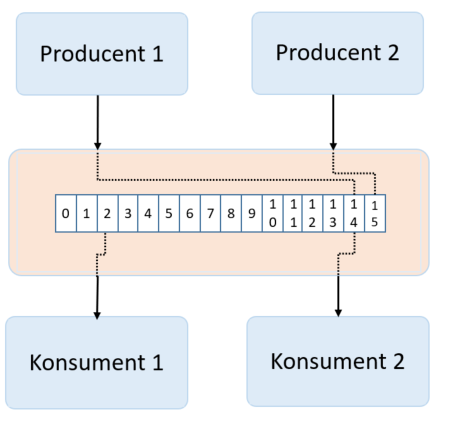
W powyższym przykładzie mamy dwóch producentów i dwóch konsumentów. Producent 1 zapisał rekord 14. Producent 2 zapisał rekord 15. Konsumer 1 sczytuje wiadomość 2. Natomiast Konsument 2 odczytuje wiadomość 14. Sekwencja danych w systemach kolejkowych nazywana jest partycją.
Topic
W naszym przykładzie Producent 1 produkuje dane innego typu niż Producent 2. Dajmy na to:
- Producent 1 – produkuje dane feedbacku do marketingu (jaki przycisk, na jakiej stronie został kliknięty, jaką stronę otwarto, z jakiego urządzenia, …)
- Producent 2 – produkuje wiadomości do powiadamiania użytkowników o różnych zdarzeniach w systemie (blokada środków na koncie, niedostępność systemów, ,…)
Bez sensu jest, aby wiadomości te znajdowały się w jednym pliku. Zróbmy zatem dwa pliki, które będą przetrzymywały wartości „określonego typu”. Wprowadzimy tu pojęcie Topic – czyli szyna danych, która grupuje komunikaty. Topic może być rozbity na wiele partycji. W poniższym przykładzie jeden topic zawiera jedną partycję.
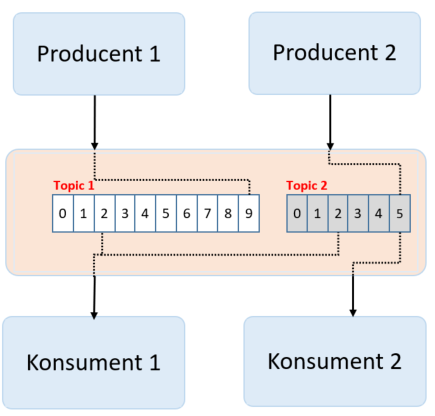
Na powyższym zdjęciu mamy dwóch producentów, dwóch konsumentów i dwa topiki. Producent 1 produkuje dane feedbacku do Topiku 1. Producent 2 produkuje wiadomości klienta do Topicu 2. Konsument 1 subskrybuje dane z obu topików. Konsument 2 subskrybuje tylko wiadomości klienta z Topiku 2.
Broker
To nic innego jak instancja Systemu Kolejkowego. Może to być fizyczny serwer, POD czy wirtualna maszyna. Zawiera w sobie topiki i partycje.
Potencjalne problemy (High Availability)
System działa i wydaje się bardzo prosty. Wystarczy zaimplementować kilka funkcji piszących na końcu pliku i kilka funkcji odczytujących plik. Nie jest to natomiast system, który nada się na środowiska produkcyjne, ponieważ co by się stało w przypadku awarii dysku, w konsekwencji utracie danych z całego topiku? Możliwa jest również awaria serwera brokera kolejki, wówczas również nie mielibyśmy dostępu do komunikacji. Problem pojawi się również przy awarii konsumenta. Wyobraźmy sobie, że mamy dwóch konsumentów czytających jeden topic. Obciążenie rozkłada się po połowie na konsumenta. Jeśli jeden z konsumentów ulegnie awarii, drugi powinien przejąć 100% ruchu. Są to wymogi High Availability, które sprawiają, że przy awarii dowolnego komponentu, system dalej działa.
Awaria producenta
Kiedy producent ulegnie awarii – nic się nie dzieje. Po prostu dane nie są publikowane na topic.
Awaria instancji brokera
Nieco większym problemem jest awaria instancji brokera. Najłatwiejszym rozwiązaniem wydaje się postawienie kopii brokera, który będzie zawierał kopie topików. Producent wysyła 50% danych do jednego brokera i 50% danych do drugiego brokera. Przydałby się jeszcze komponent, który będzie zarządzał tym, gdzie trafiają konkretne dane od strony producenta, a od strony konsumenta – z którego brokera czytać, aby zachować prawidłową kolejność komunikatów. Ten komponent to Zookeeper. Spójrzmy na fotografię poniżej.
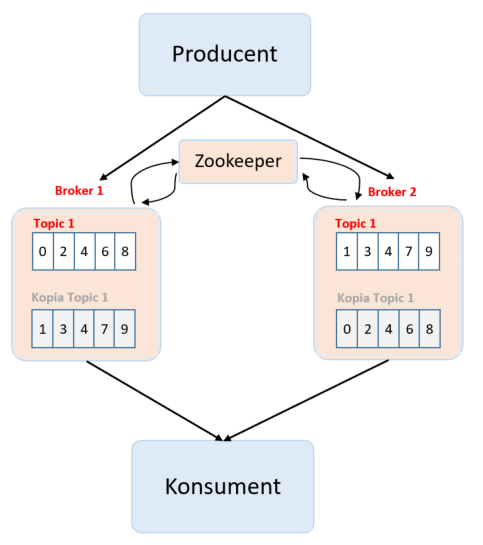
Na powyższej fotografii mamy jednego producenta i jednego konsumenta. Pojawiły się natomiast dwie instancje brokerów i Zookeeper. Broker 1 zapisuje 50% danych od producenta. Drugie 50% danych jest zapisywane na instancji Broker 2. Ponadto Broker 1 posiada kopię topiku z Brokera 2, który z kolei posiada kopię topiku z Brokera 1. Tajemniczy Zookeeper to moduł, który zarządza tym, gdzie dane wiadomości powinny trafić. Konsumenta nie interesuje, to z czy dane odczytuje z oryginału, czy z kopii bezpieczeństwa. Konsumer subskrybuje konkretną kolejkę. Brokerzy nie zdają sobie sprawy, że istnieje inny broker, który przechowuje kopię bezpieczeństwa albo część danych. Całym ruchem zarządza Zookeeper. Jesteśmy więc zabezpieczeni przed awarią konkretnego noda. Kiedy awarii ulegnie Broker 2, system dalej działa, mamy gwarancję, że nie stracimy danych.
Awaria konsumenta
A co w przypadku awarii konsumenta? Spójrzmy na poniższą fotografię.
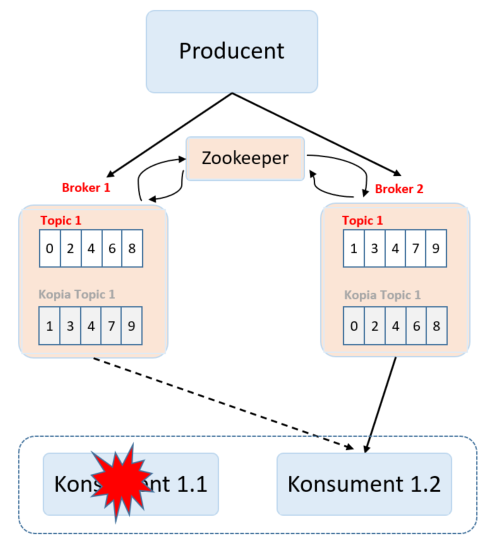
Mamy dwóch konsumentów tego samego topika – Konsument 1.1 i Konsument 1.2. Posiadają oni ten sam kod, a ruch jest rozdzielany po równo pomiędzy instancje konsumentów. Podczas bezawaryjnej pracy systemu, Konsument 1.1 odczytuje 50% danych, a Konsument 1.2 odczytuje pozostałe 50% danych. W przypadku awarii Konsumenta 1.1 – drugi konsument przejmuje obsługę wszystkich wiadomości. Pojawia się kolejny problem. Skąd drugi konsument ma wiedzieć, gdzie skończył czytać pierwszy konsument – co za tym idzie – od jakiej wiadomości ma zacząć czytanie, tak aby nie podejmować komunikatów już przetworzonych lub nie pominąć żadnych komunikatów. Gdzieś musimy przechowywać stan o ostatnio odczytanym komunikacie – tak aby wiedzieć, od czego zacząć. Dochodzi nowe pojęcie – offset – to właśnie offset przechowuje informacje o ostatnio odczytanym rekordzie. Teraz trzeba się zastanowić, gdzie umieścić tę informację. Skoro nasze brokery są swoistym „magazynem danych” – tam zapiszmy informację o offsecie. Zaprezentowałem to na poniższej fotografii.
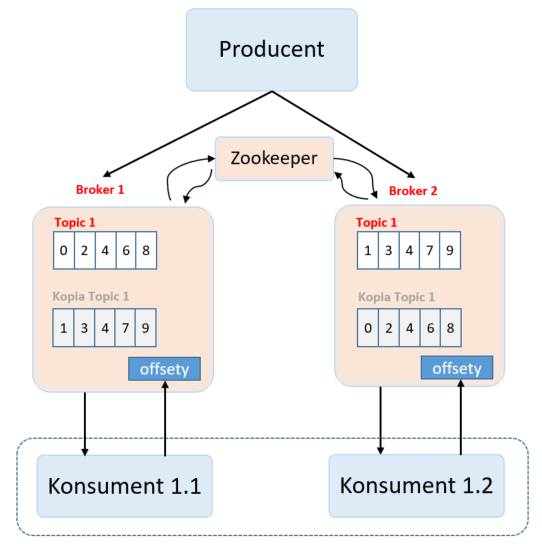
Oboje konsumenty oprócz subskrybowania danych, aktualizują swój stan ostatnio przetworzonych wiadomości. Przykładowo konsument może odczytywać pojedyncze rekordy lub paczki rekordów. W trakcie bezawaryjnej pracy – po przetworzeniu porcji danych – zapisuje pozycję offset ostatnio przetworzonego rekordu w brokerze, a następnie dostaje następną porcję danych. W przypadku awarii pierwszego konsumenta – drugi przejmuje jego rolę. Dzięki zapisanej pozycji ostatnio przetworzego rekordu, drugi konsument wie, z jakiej pozycji zacząć procesować komunikaty.
Apache Kafka – wydajność vs. gwarancja dostarczenia wiadomości
Jak stworzyć piekielnie szybką albo maksymalnie bezpieczną wersję producenta oraz konsumenta.

Inne problemy / wyzwania
Coraz bardziej dopracowujemy model naszego systemu kolejkowego, ale jak to zwykle bywa – po drodze mamy kilka wyzwań, które trzeba zaopiekować.
- Dyski nie mają nieograniczonej pojemności. To pierwszy problem, który napotykamy. Piszemy do pliku, dodając nowy rekord na jego końcu. Wyobraźmy sobie, że produkujemy kilka milionów rekordów na sekundę. Rekordy te są sukcesywnie odczytywane i przetwarzane przez konsumentów, pomimo tego zostają na dysku i zajmują miejsce. Rozwiązaniem jest znów analogia do logów. Nie raz je pewnie widziałeś/aś. Zaobserwować można, że logi powstają „do pewnego rozmiaru” albo „do pewnego czasu”. Zazwyczaj codziennie tworzony jest nowy plik z logami z danego dnia. Również w systemie kolejkowym powinniśmy podzielić nasz topic na segmenty i te przetworzone usuwać po jakimś czasie.
- Pobieranie wiadomości o konkretnym offsecie. Zazwyczaj producent zapisuje nowe rekordy szybciej niż konsument nadąża z ich przetworzeniem. Rzadko kiedy zdarza się taka sytuacja, kiedy to konsument odczytuje zawsze ostatni rekord. Przeważnie wygląda to tak: „daj mi rekord o offsecie = offset + 1”. Może się zdarzyć tak, że wiadomość o danym offsecie jest w środku pliku, gdzie przechowywane są wiadomości. Występuje kolejny problem nieoptymalnego przeszukiwania pliku, aby wyciągnąć konkretną wiadomość. Z pomocą przychodzą indeksy (tak, z baz danych), które jak spis treści w książce – segregują dane, a dostęp do posegregowanych wiadomości staje się niemal liniowy.
Wydaje się, że rozwiązaliśmy kluczowe problemy, które blokowały nam wysoką dostępność systemu kolejkowego. Tak się składa, że to co opisywaliśmy – to właśnie Apache Kafka!
Kilka słów o Apache Kafka
Apache Kafka była lekiem na problemy LinkedIn, gdzie borykano się z problemem ogromnej ilości komunikatów (ok. 7 milionów komunikatów na sekundę!). Twórcy LinkedIn wymyślili i wdrożyli system kolejkowy Kafka. Niedługo potem projekt dostał status open source i przejęła go firma Apache. Dziś z Apache Kafka korzystają tacy globalni liderzy jak: Netflix, Twitter, Spotify, Cisco, czy wspomniany LinkedIn.
Apache Kafka to tak zwany message broker. Kafka odpowiada za produkcję, odbieranie czy rozsyłanie wiadomości pomiędzy aplikacjami, tworząc bardzo elastyczny sposób komunikowania się luźno powiązanych ze sobą części systemu. Cechą charakterystyczną tej kolejki jest bardzo duża niezawodność, niezwykła wydajność umożliwiająca obsługę dziesiątki milionów wiadomości na sekundę, czy zdolność do pracy w środowisku rozproszonym.
Architektura Apache Kafka
We wcześniejszych akapitach przybliżyłem Ci, w jaki sposób działa Kafka. Spróbujmy sobie to podsumować.
Komunikaty w Kafce pogrupowane są w tzw. tematy (ang. topic). Nadawca (producent), jak i odbiorca (konsument) powiązani są z danym topikiem. Jeden topik może być zasilany danymi z kilku producentów. Tak samo kilku konsumentów może nasłuchiwać jeden topik (i to w różnych trybach – albo każdy dostaje ten sam komunikat, albo każdy dostaje część komunikatów – o czym później). Kafka może być replikowana na wielu serwerach, co zapewnia wysoką dostępność w razie awarii jednego albo kilku z nich. Pojedynczy serwer – instancja Kafki to tzw. broker wiadomości. Rejestry komunikatów (partycje) z danego tematu mogą być replikowane na wiele maszyn jednocześnie (na instancje brokerów).
Komunikaty z danego topiku dopisywane są na końcu tzw. partycji (ang. partition). Partycja to uporządkowany rejestr komunikatów (jak w przykładzie z logami). Mówiąc niskopoziomowo, jest to plik na dysku brokera, do którego zapisywane są logi (komunikaty). Aby konsument był w stanie odebrać określony komunikat / sekwencję komunikatów – musi znać pozycję ostatnio przeczytanego komunikatu – offset.
Rozmiar partycji może być na tyle duży, aby zmieściła się ona na jednym serwerze. Musi być możliwość obsłużenia partycji przez jednego brokera. Większa ilość brokerów zwiększa wydajność klastra, zrównoleglając operacje odczytu i zapisu. Apache Kafka gwarantuje wydajne działanie nawet do 10 000 partycji.
W systemach ze znaczną ilością danych może dojść do sytuacji, że wszystkie komunikaty nie zmieszczą się na jednej partycji. Dla tego Kafka zezwala na sytuację, w której jeden topik jest podzielony na x partycji, które z kolei mogą już być obsługiwane przez różnych brokerów.
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
Partycje są replikowanie, czyli ich kopie mogą znajdować się na wielu serwerach. Dla każdej partycji istnieje jeden serwer, który pełni funkcję tzw. lidera – obsługuje on wszystkie operacje zapisu i odczytu na danej partycji. Jeśli partycji jest więcej (np. poziom replikacji ustawiony na 3) – będziemy mieli jednego lidera i 2 brokerów, którzy tylko kopiują dane na 2 pozostałe partycje, w celu zwiększenia bezpieczeństwa klastra.
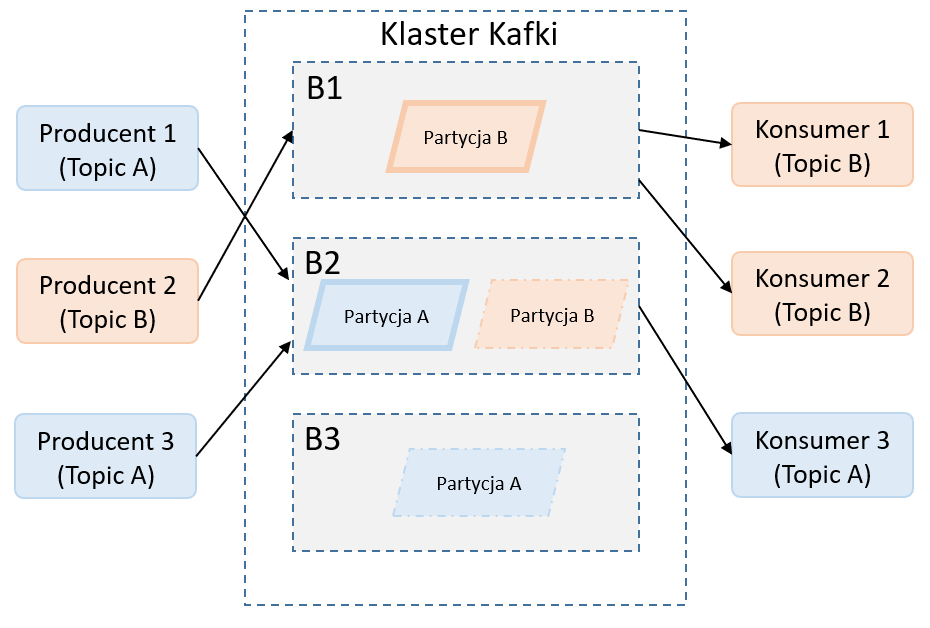
Na powyższym zdjęciu prezentuje przykład klastra Kafki, który składa się z:
- trzech brokerów: B1, B2, B3
- dwa topiki (A i B)
- dwie partycje (po jednej na topik)
- trzech producentów wiadomości
- trzech konsumentów wiadomości
Broker B2 jest liderem dla topiku A. Broker B1 jest liderem dla topiku B. Partycja B na brokerze B2 jest kopią partycji z brokera B1. Partycja na brokerze B3 jest kopią partycji A z brokera B2. W przypadku awarii borkera B2 rolę lidera dla topika A przejmie B3. Ponadto zostaną utworzone nowe kopie partycji A i B na działających instancjach brokera.
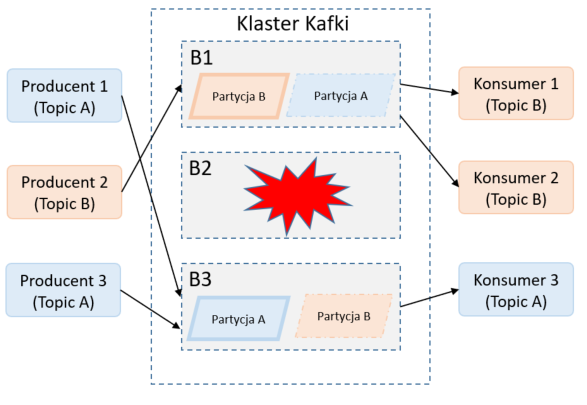
To na ilu serwerach znajdzie się kopia partycji, jest regulowane przez tzw. współczynnik replikacji. Dla współczynnika replikacji wynoszącego N może dojść do awarii N – 1 brokerów, aby system działał dalej.
Grupy konsumentów
Może się zdarzyć taka sytuacja, kiedy:
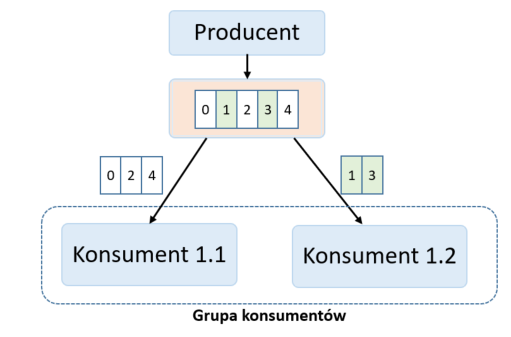
- Chcemy, aby ruch z topiku był rozkładany pomiędzy dwóch konsumentów, tak aby zrównoleglić procesowanie wiadomości i zabezpieczyć konsumentów przed awarią, któregoś z nich. Wówczas będzie nam zależało na tym, aby każdy z konsumentów dostał część wiadomości (żeby się nie powielały). Prezentuje to schemat poniżej, gdzie oba konsumenty znajdują się w tej samej grupie konsumentów (parametr group-id). Konsument 1.1 odczyta komunikaty 0, 2 i 4. Konsument 1.2 odczyta pozostałe komunikaty, czyli 1 i 3.
- Inna sytuacja to taka, kiedy chcemy, aby konsumenci odczytywali te same dane (żeby nie podbierali sobie komunikatów). Jako przykład można dodać kolejkowanie zmian danych użytkownika. Kiedy dołącza nowa aplikacja, która chce historię zmian użytkownika – dołącza do kolejki, subskrybuje topic z użytkownikami. Żeby konsument dostał wiadomości od początku (a nie od ostatnio odczytanego offsetu) – musi ustawić swoją grupę, na taką, której jeszcze nie ma. Prezentuje to poniższy slajd.
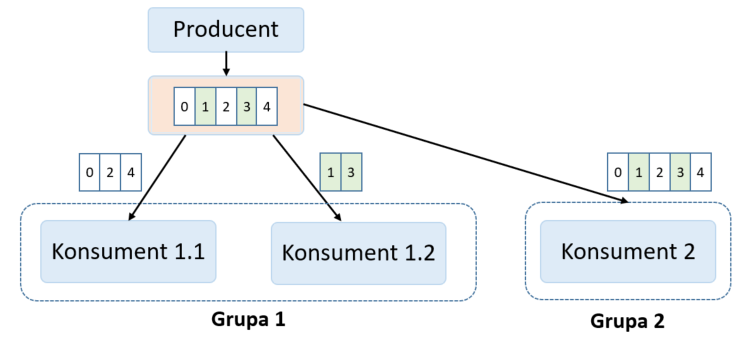
W tym przykładzie Konsument 1.1 i Konsument 1.2 należą do tej samej grupy wiadomości – Grupa 1. Komunikacja zostanie więc podzielona po równo pomiędzy dwóch konsumentów. Konsument 2 należy do innej grupy – dostanie więc całą komunikację.
Gwarancje
W Apache Kafka rozróżniamy trzy rodzaje gwarancji dostarczenia komunikatów. Są to:
- Co najwyżej raz – wiadomości mogą zostać utracone, ale na pewno wiadomość nie zostanie wysłana wiele razy. Przydatne przy wszelkiego rodzaju danych statystycznych, gdzie nie zaboli nas utrata pojedynczych komunikatów
- Przynajmniej raz – wiadomość może zostać odebrana ponownie, ale na pewno żadna z nich nie zostanie utracona. Jest to domyślna konfiguracja.
- Dokładnie raz – każdy komunikat zostanie dostarczony dokładnie jeden raz do odbiorcy. Przydatne w systemach bankowych, gdzie nie chcemy, aby przelew wykonał się kilka razy, albo kasa znikła z konta, a przelew nie wyszedł.
Kilka ciekawostek o Apache Kafka
Na sam koniec przedstawię Ci kilka ciekawostek o kolejkach Kafki:
- Kafka nie cachuje danych – to system kolejkowy, nie służy on jednak do cachowania danych. Operacje na plikach, pomimo coraz szybszych dysków, nadal są bardzo ciężkie. Czemu więc Kafka nie implementuje jakiegoś cache? A no dlatego, że Kafka nie odczytuje danych „bezpośrednio z pliku”. Władzę nad plikiem przejmuje system operacyjny. Kiedy odczytujemy jeden konkretny rekord z pliku, system operacyjny wczytuje kilkaset (lub więcej) następnych rekordów do pamięci operacyjnej. Dzieje się tak, ponieważ SO zakłada, że skoro potrzebujemy tej jednej danej, to wielce prawdopodobne jest, że za niedługo będziemy potrzebować danej, która znajduje się w pobliżu tej odczytywanej i na własną rękę cachuje ten fragment pliku. Kafka po prostu sprytnie to wykorzystuje.
- Kafka nie przechowuje konfiguracji – wyobraźmy sobie, że do naszego systemu dochodzi nowy topic, do którego dostęp ma tylko aplikacja X . Ciężko byłoby powiadamiać wszystkich brokerów o zmianach. W zamian Kafka wykorzystuje Zookeeper, w którym przechowywuje wszystkie dane konfiguracyjne klastra. Wszyscy brokerzy odpytują się Zookeeper w celu pobrania instrukcji jak mają pracować i jak dystrybuować dane. Zookeeper to swego rodzaju źródło prawdy.
- Zookeeper zniknie w przyszłych wersjach kafki. Kafka aktualnie wykorzystuje Zookeeper jako źródło prawdy. Są plany, aby w nowszych wersjach Kafki, pozbyć się Zookeepera i zastąpić go własną implementacją.
- Kafka kompaktuje dane – wiadomość na kafce ma postać <klucz, wartość>, gdzie mogą to być dowolne dane (nie ma jednego standardu). Jeśli jako klucz podamy losową wartość – dane będą rozrzucane losowo po różnych partycjach w ramach jednego topiku (a Kafka gwarantuje kolejność komunikacji tylko w ramach jednej partycji). Kolejność komunikatów wśród różnych partycji nie jest zachowana, co może stanowić problem przy transakcyjnych komunikatach. Wyobraźmy sobie, że na kafke wrzucamy dane użytkownika. Możemy wówczas jako klucz podać jego identyfikator. Wtedy Kafka będzie odkładała wiadomości o tym samym kluczu (id usera) na jednej partycji – nie będzie ich rozrzucała losowo po partycjach topicu. Wtedy na podstawie klucza jesteśmy w stanie wyciągnąć całą historię komunikacji, zachowując jej kolejność.
Zakończenie
Gratulacje, jeśli dotrwałeś/aś do końca tego długaśnego artykułu. Oczywiście to nie koniec informacji o Apache Kafka (to tylko wstęp:)). W kolejnych artykułach pokażemy:
- Jak uruchomić Apache Kafka w wersji konsolowej – tak aby przećwiczyć teoretyczne informacje.
- Czym jest Avro – czyli jak dbać o strukturę wiadomości i kompatybilność schematów.
- Czym jest Schema Registry – czyli kilka słów o zarządzaniu schematami avro.
- Konfiguracja konsumenta i producenta w czystej Javie.
- Konfiguracja konsumenta i producenta w Spring.
Jeśli nie chcesz, aby ominęły Cię artykuły – zapisz się do naszego newslettera – a pierwszy/pierwsza otrzymasz powiadomienie, prosto na swój adres email o nowym artykule,
Na koniec mam do Ciebie ogromną prośbę. Dla twórcy bardzo ważni są czytelnicy. Będę bardzo wdzięczny, jeśli podzielisz się niniejszym wpisem w kanałach social media. A jeśli jeszcze nie polubiłeś naszego FanPage na FaceBook – tu jest link https://www.facebook.com/softwareskill
Wpis który czytasz to zaledwie fragment wiedzy zawartej w Programie szkoleniowym Java Developera od SoftwareSkill. Mamy do przekazania sporo usystematyzowanej wiedzy z zakresu kluczowych kompetencji i umiejętności Java Developera. Program składa się z kilku modułów w cotygodniowych dawkach wiedzy w formie video.
Podsumowanie
Kafka to złożony system kolejkowy, wykorzystywany przez największe firmy. Warto jest zapamiętać następujące rzeczy:
- Każda partycja związana jest z jednym tematem.
- Rejestr komunikatów z danego topiku może być rozbity na wiele partycji.
- Partycja może być replikowana.
- Każda z partycji musi zmieścić się na pojedynczej instancji Kafki (pojedynczym brokerze)
- Większa liczba partycji pozwala na zwiększenie wydajności operacji odczytu i zapisu komunikatów.
- Większy współczynnik replikacji pozwala na zwiększenie bezpieczeństwa danych (odporność klastra na awarie).
Podsumowując, producent wysyła wiadomość do brokera. Wiadomość trafia do odpowiedniego topika, który składa się z jednej lub wielu partycji (czyli fizycznego pliku na dysku). Konsument odczytuje wiadomości z konkretnego topiku (subskrybując go). Po odczytaniu aktualizowana jest pozycja offsetu. Proste, prawda? 🙂
Podoba Ci się ten artykuł? Weź więcej.
Jeżeli uważasz ten materiał za wartościowy i chcesz więcej treści tego typu – nie przegap ich i otrzymuj je prosto na swoją skrzynkę. Nawiążmy kontakt.
Gdybyś potrzebował jeszcze więcej:
Jesteś Java Developerem?
Przejdź na wyższy poziom wiedzy
„Droga do Seniora” 🔥💪
Jesteś Team Leaderem? Masz zespół?
Podnieś efektywność i wiedzę swojego zespołu 👌
