Testy obciążeniowe systemu (performance testing) pozwalają na ocenę wymagań niefunkcjonalnych dotyczących założeń ilości przetwarzanego ruchu w aplikacji (transakcji na sekundę), obserwowania zachowania aplikacji (pauzy Garbage Collector, wycieki pamięci, zachowanie wątków, obserwacja I/O). Zadaniem testów obciążeniowych jest wygenerowanie założonego ruchu, rejestrację metryk i wyciągnięcie wniosków.
Z tego artykułu dowiesz się
- Jakie są rodzaje metryk i jak je interpretować (średnia, mediana, percentyl, troughput, latency)
- Co mierzyć w aplikacji
- Jakie są typy testów performance
- Na co zwrócić uwagę podczas konfigurowania środowiska
- Przydatne narzędzia w Java do performance testing
Piguła wiedzy o najlepszych praktykach testowania w Java
Pobierz za darmo książkę 100 stron o technikach testowania w Java

Metryki
Aby zacząć interpretować wyniki testów kluczowe jest zrozumienie podstaw statystyki, aby wiedzieć, na jakie metryki zwracać uwagę, jak one działają i w rezultacie co one wskazują.
Aby umieścić metrykę jako pojedynczą wartość na ciągłym wykresie czasowym, należy kwantyfikować ją w postaci agregowanej wartości wszystkich obserwacji, które wystąpiło w danym oknie czasowym. Jeżeli dana metryka jest raportowana co 5 sekund, wszystkie obserwacje są zliczane w jedną wartość, aby umieścić ją jako punkt na wykresie czasowym.
Średnia
Średnia to wartość wyliczana na podstawie zsumowania wszystkich wyników i podzieleniu przez ich liczbę. Metryka działa dobrze, gdy odchylenie standardowe obserwowanej metryki nie jest duże, jest skupione wokół tej wartości. Trzeba wiedzieć, że średnia ukrywa wartości skrajne (min i max). Z perspektywy testów performancowych nie zauważymy niczego niepokojącego, jeżeli aplikacja dla pewnych przypadków będzie działała dużo wolniej.
Mediana
Mediana to inaczej wartość środkowa. Obserwacje w oknie czasowym są sortowane rosnąco, a następnie wybierana jest środkowa wartość. Mediana odkrywa potencjalne duże odchylenie standardowe, gdy wyniki koncentrują się wokół jakiejś wartości, ale występują również wartości skrajnie wysokie, które podbiłyby średnią. Z perspektywy testów performanceowych – mediana nadal ukrywa skrajnie wysokie wartości.
Percentyl
Percentyle służą do zrozumienia i interpretacji wyników. Wskazują one wartości, poniżej której znajduje się pewien procent danych w zbiorze danych. N-ty percentyl zestawu danych jest wartością, w którym n procent danych jest poniżej. Zatem percentyl bazuje na posortowanych rosnąco wartościach.
Z punktu widzenia performance testing i pomiaru czasu odpowiedzi systemu, pytając o 95 percentyl (p95) otrzymamy wartość, dla której 95% przypadków było lepszych (odpowiedź z systemu trwała krócej), a 5% buło gorszych (trwało dłużej).
Jest to najbardziej interesująca nas metryka, zważając na jej cechy, w kontekście, gdy zależy nam na obserwacji najgorszych przypadków czasu przetwarzania i odpowiedzi na pytanie ile one wynoszą.
Throughput
Throughtput, czyli przepustowość, to metryka mówiąca nam ile operacji zostało wykonanych w jednostce czasu. Jeżeli throughtput aplikacji to 150 req/s to zostaje przetwarzanych 150 żądań na sekundę. Jeżeli coś jest wyrażane np. na sekundę, niekoniecznie musi być mierzone co sekundę – może być to agregat co 10 sekund (optymalizacja), natomiast oznacza się go w standardowej jednostce czasu dla czytelności.
Przy interpretacji wyników należy ocenić, czy uzyskana przepustowość to zadana, czy maksymalna. Może nie został wygenerowany odpowiednio duży ruch. Jeżeli przepustowość zadana > przepustowość aplikacji, oznacza to, że aplikacja nie nadąża z generowaniem odpowiedzi.
Latency
Latency, czyli opóźnienie, to czas mierzony od zgłoszenia żądania do momentu uzyskania odpowiedzi. Latency zasadniczo można podzielić na kilka części:

- t1 – Czas transportu żądania. Liczony od wysłania żądania przez klienta do systemu do momentu otrzymania go.
- t2 – Czas oczekiwania na realizację. Jeżeli przepustowość aplikacji nie jest wystarczająca, żadania tworzą kolejkę do wykonania – nie są wykonywane od razu.
- t3 – Czas realizacji zadania.
- t4 – Czas transportu odpowiedzi. Podobnie jak czas t1, ale z odesłaniem odpowiedzi.
Wysokie latency niekoniecznie oznacza, że aplikacja nie nadąża – należy sprawdzić througput i to, czy latency rośnie. Może bowiem się okazać, że przetwarzanie zawsze wynosi 100ms (dużo operacji I/O, opóźnienie sieci), ale aplikacja realizuje zadania na bieżąco. Jeżeli jednak aplikacja zaczyna nie nadążąć z przetwarzaniem, czas oczekiwania żądania na realizacje stale się wydłuża, tak długo, aż liczba requestów nie zaczyna spadać – wtedy aplikacja ma szansę na obsłużenie oczekujących żądań.
Co mierzyć
Czasy przetwarzania z podziałem na typ operacji
Dobrze jest mierzyć czasy przetwarzania poszczególnych typów requestów. Jeżeli Twoja aplikacja eksponuje kilkadziesiąt przypadków użycia – zmierz czasy przetwarzania dla każdego z nich z osobna. Może okazać się, że tylko część operacji nie jest wystarczająco wydajna i skutecznie zawęzisz obszar poszukiwań.
Czasy dostępu do zewnętrznych zasobów
Dobrze jest mierzyć czasy dostępu do zewnętrznych zasobów – wszelkiego rodzaju I/O. To one zazwyczaj zwiększają latency naszej aplikacji. Zewnętrznymi zasobami może być: dostęp do bazy danych, żądanie do innego serwisu, dostęp do dysku. Dobrze jest mieć osobne metryki na każdy zasób, idealnie z podziałem na rodzaj operacji.
Pamięć JVM
Podczas przeprowadzaniu testów obciążeniowych warto monitorować stan pamięci (generacje Young i Old). Pozwoli to zidentyfikować potencjalne:
- Wycieki pamięci – jeżeli pamięć stale narasta i działanie GC nie zwalnia pamięci blisko do poprzedniego poziomu, oznacza to fragment do analizy wycieku pamięci.
- Problemy z kolejkami in-memory przed Executor pulami.
Jeżeli przed executor pulą nagromadzi się wystarczająco dużo żądań do przetworzenia, w końcu skończy się na nie pamięć. Warto znać tę granicę, aby odpowiednio dobrać rozmiar kolejki i nie przyjmować kolejnych żądań.
Pauzy Garbage Collector’a
Chwilowe spadki czasu przetwarzania mogą być związane z pauzami Garbage Collector’a. Dobrze jest mieć zanotowane, kiedy takie pauzy nastąpiły i ile czasu trwały, aby ewentualnie móc skorelować to zdarzenie.
Metryki otoczenia (CPU)
Na chwilowy spadek performance naszej aplikacji może mieć również wpływ otoczenia zewnętrznego. Jeżeli uruchamiamy aplikację w niewyizolowanym środowisku zapewniającym pewien poziom CPU (bez wywłaszczania), na działanie aplikacji może mieć wpływ inna aplikacja. Warto jest notować % zużytego CPU w systemie.
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
Typy testów performance
Można wyróżnić kilka klas testów obciążeniowych w zależności od tego, jaki jest cel testu.
Burst
Burst, czyli impuls, oznacza generowanie żądań na stałym poziomie (np. 10/s przez 30s), aby po jakimś czasie wygenerować pik (np. 300/s przez 1s). Cel: Tego typu test określi, w jakim czasie aplikacja powróci do normalnego przeważania, jeżeli nagle otrzyma pik ruchu (jeżeli throughput jest mniejszy niż 300r/s, pewnie odłożą się na pewnej kolejce zadań).

Ramp up
Ramp up test to stale zwiększany ruch, trwający określony czas, np. startując od 10 r/s, co 10 sekund zwiększany jest o kolejne 10/s. Cel: Takie małe delty pozwalają na określenie punktu krytycznego, po którym aplikacja zaczyna nie nadążać z serwowaniem odpowiedzi. W takim wypadku na wykresie latency odpowiedzi będziemy obserwowali wykładniczy wzrost czasu przetwarzania – tzw „kosę” w górę.

Long running
Long running test to warunki, w których ruch jest jednostajnie wysoki, ale test trwa długo (np. godzinę). Cel: Pozwala to na obserwację, jak zachowuje się aplikacja pod stałym obciążeniem – co się dzieje z pamięcią, czy istnieją wycieki pamięci.
Środowisko
Generuj ruch z innej maszyny
Kluczowym jest wyizolowanie środowiska uruchomieniowego aplikacji od środowiska, w którym generowany jest ruch. Dzięki temu wyniki nie będą zaburzone procesem generowania ruchu do aplikacji.
Konfiguracja zbliżona do produkcji
Istotnym jest, aby warunki, w jakich aplikacja jest testowana były jak najbardziej zbliżone warunkom na produkcji. Nie zawsze jest to możliwe, ale postaraj się:
- Zachować te same kolokacje zasobów. Jeżeli baza danych lub systemy z którymi się łączysz są w innym Data Center (albo nawet w innym regionie) – postaraj się o takie samo rozmieszczenie środowiska testowego. Unikniesz sytuacji, w której będziesz testował system skonfigurowany w jednym DC na środowisku testowym, a w rzeczywistości jest bardziej rozproszone, co wpływa na ogólną wydajność.
- Używać tych samych wersji i wariantów oprogramowania, np. silnika bazy danych, lub silnika w Cloud (zamiast lokalnie uruchomionej instancji).
- Aplikacja ma podobny dostęp do zasobów. Unikaj sytuacji, w której na produkcji aplikacja może mieć przydzielone mniej CPU, niż na środowisku testowym. Jeżeli testujesz na znacznie gorszej maszynie – możesz spodziewać się lepszych wyników na produkcji, ale testy performance udowodnią wersję minimum.
Zerowy, czysty stan
- Zrestartuj aplikację. Postaraj się, aby aplikacja miała świeży stan przed testowaniem testowania Przed pomiarami możesz wykonać rundę rozgrzewkową żądań, aby JIT (just-in-time compiler zoptymalizował kod).
- Opróżnij zasoby. Jeżeli używasz systemów kolejkowych – przed i po teście opróżnij kolejki, aby testy nie „nachodziły” na siebie. Usuń narastające dane w bazie danych.
- Posprzątaj po teście, jak w kroku poprzednim. Najlepiej zrobić to przed i po teście. Przed, na wypadek, gdyby poprzednie uruchomienie tego nie wykonało.
Narzędzia
W performance testing potrzebujemy zasadniczo dwóch rodzajów nazędzi:
- Generujących obciążenie
- Rejestrujących wyniki
- Automatyzacji procesu (narzędzia typu Contineous Integration)
Gatling
Gatling (https://gatling.io/) to narzędzie, w którym będziesz w łatwy sposób mógł przygotować scenariusze testowe, wygenerować odpowiedni ruch i wysłać go za pomocą HTTP, WebSocket, SSE (Server-Sent Events) lub JMS. Dodatkową zaletą jest jego wydajność.
Przykładowy scenariusz:
setUp(scn.inject(constantUsersPerSec(100) during (30 minutes))).throttle(
reachRps(100) in (10 seconds),
holdFor(1 minute),
jumpToRps(50),
holdFor(2 hours)
)
JMeter

Apache JMeter (https://jmeter.apache.org/) to narzędzie starszej daty, ale realizuje swoje funkcje. Jest wolniejszy od Gatling. Posiada GUI, w ktorym można dosłownie wyklikać scenariusze testowe. Następnie zapisane jako pliki można je uruchamiać z GUI (niska wydajność) lub z CLI (jako command line tool lub plugin mavenowy do projektu).
Java Flight Recorder (JFR)
Java Flight Recorder to narzędzie wbudowane w JDK służące do monitorowania stanu JVM. Można się zdalnie podłączyć do procesu lub rozpocząć nagrywanie bezpośrednio przy starcie aplikacji. Nagrywanie polega na zbieraniu próbek z aplikacji rejestrujących zdarzenia w JVM (np, zużycie pamięci, GC, I/O, CPU, zachowania wątków, hotspotów kodu, itd.). Bardzo przydatne w diagnozowaniu przyczyny probelmu.
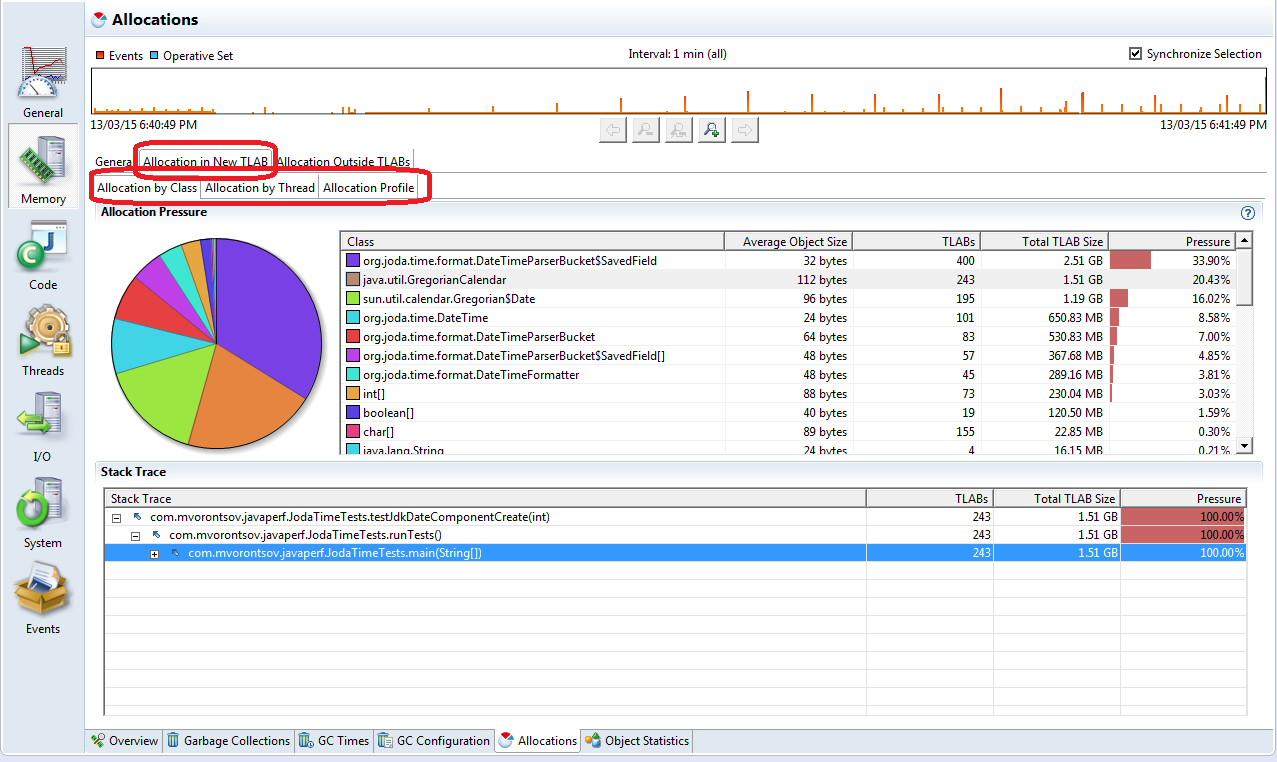
Micrometer
Micrometer (https://micrometer.io/) to biblioteka do zbierania metryk bezpośrednio z aplikacji. Jest to fasada na różne implementacje wysyłania metryk. Istnieje gotowa integracja ze Spring Boot, ale można rejestrować własne metryki. Jako standardowe metryki otrzymujesz statystyki CPU, Pamięci, GC.
Graphite + Grafana
Metryki z aplikacji należy gdzieś składować i je wizualizować.
W tym zakresie polecam Graphite (https://graphiteapp.org/) jako bazę danych czasowych (RRD – round-robin database)
Grafana (https://grafana.com/) to narzędzie do wizualizacji dashboardów. Z łatwością zwizualizujesz dane wyklikując panele monitoringu. Możesz również tworzyć alerty.

Zipkin
Zipkin (https://zipkin.io/) to narzędzie do śledzenia systemów rozproszonych. Pozwala na określenie latency pomiędzy systemami, jaki request ile czasu spędził w poszczególnych systemach. Oprócz zebrania tych danych Zipkin pozwala je wizualizować.
Narzędzie przydatne w kontekście systemów rozproszonych, wyniki można przeglądać w pojedynczych i zagregowanych formach śledząc dany odsetek requestów.

Podsumowanie
Performance testing służy do zweryfikowania wymagań niefunkcjonalnych związanych z przepustowością i stabilnością systemu. Projektując proces performance testingu wiesz już:
- Jakie są metryki i w jaki sposób działają.
- Co warto opomiarować.
- Jak wykonać testy.
- Jakie są przydatne narzędzia, z których możesz skorzystać.
Powodzenia!
Piguła wiedzy o najlepszych praktykach testowania w Java
Pobierz za darmo książkę 100 stron o technikach testowania w Java
Podoba Ci się ten artykuł? Weź więcej.
Jeżeli uważasz ten materiał za wartościowy i chcesz więcej treści tego typu – nie przegap ich i otrzymuj je prosto na swoją skrzynkę. Nawiążmy kontakt.
Gdybyś potrzebował jeszcze więcej:
Jesteś Java Developerem?
Przejdź na wyższy poziom wiedzy
„Droga do Seniora” 🔥💪
Jesteś Team Leaderem? Masz zespół?
Podnieś efektywność i wiedzę swojego zespołu 👌
Obraz: Logo plik wektorowy utworzone przez freepik – pl.freepik.com
