Podczas komunikacji pomiędzy zintegrowanymi systemami może dojść do krótkotrwałej awarii. Dobrą praktyką jest, aby aplikacja działająca w środowisku rozproszonym była odporna i przygotowana na wystąpienie tymczasowych awarii i ponawiała operację, zamiast zatrzymywać proces biznesowy. W tym wpisie, będącym kontynuacją serii o integrowaniu systemów, opiszę wzorzec ponawiania, czyli Retry Pattern, części mechanizmów odporności aplikacji (Resiliency).
Z artykułu dowiesz się:
- Czym jest i jak działa Retry Pattern
- Jakie są ustawienia (czyli Retry Policy)
- Na jakiego typu błędy reagować
- Od czego powinno zależeć to, jakie parametry ustawić
Potencjalne problemy z komunikacją
Przerwy w dostępie do usług działających w cloud nie są niczym niespotykanym.
- Serwisy podczas swojej pracy mogą być restartowane (odrzucenie żądania):
- z powodu wdrażania nowej wersji
- z powodu zmiany zeskalowania
- Dana instancja serwisu może być przeciążona.
- Mogą wystąpić krótkotrwałe problemy z siecią.
Tego typu problemy mają naturę tymczasową, samonaprawczą. Przygotowanie aplikacji na takie sytuacje spowoduje mniejszą awaryjność i kontynuację procesu biznesowego w przypadku awarii samej integracji. Pozwoli to na działania aplikacji bez konieczności manualnej interwencji.
Jeżeli awaria jest długotrwała i nie należy oczekiwać działania serwisu w rozsądnym czasie, można przerwać interakcje, zamiast nasilać problem, do czego służy Wzorzec Bezpiecznika (Circuit Breaker Pattern).
Retry Pattern
Wyobraź sobie, że istnieje OrderService, który na podstawie produktów zgromadzonych w koszyku zakupowym składa zamówienie w systemie i uruchamia proces zakupowy. W sytuacji, gdy odpowiedź zwraca błąd, mamy co najmniej 3 wyjścia:
- Przerwać operację i zgłosić błąd.
W przypadku, gdy serwis odpowiedział poprawnie, ale na przykład zgłosił błąd walidacji danych, należy przerwać dalsze operacje. Najprawdopodobniej nie przyniosą one lepszego skutku. - Spróbować ponownie.
Gdy wystąpił tymczasowy problem z siecią i połączenie zostało zerwane, aplikacja mogłaby od razu ponowić żądanie, drugie połączenie może się udać. - Poczekać i spróbować ponownie.
Może wystąpić sytuacja, która potrzebuje krótkiego odcinka czasu, aby problemy ustąpiły. W takich sytuacjach odczekujemy zadany odcinek czasu (opóźnienie), a dopiero później spróbujmy ponownie.
W przypadku wystąpienia problemów moglibyśmy ponowić operację złożenia zamówienia, np. za 200 milisekund. Jeżeli to się nie uda, spróbujmy jeszcze 4 razy (w sumie 5 razy, czyli jedna sekunda prób). Jeżeli jakaś wcześniejsza próba się powiedzie – świetnie. Podobną sytuację prezentuje schemat poniżej:
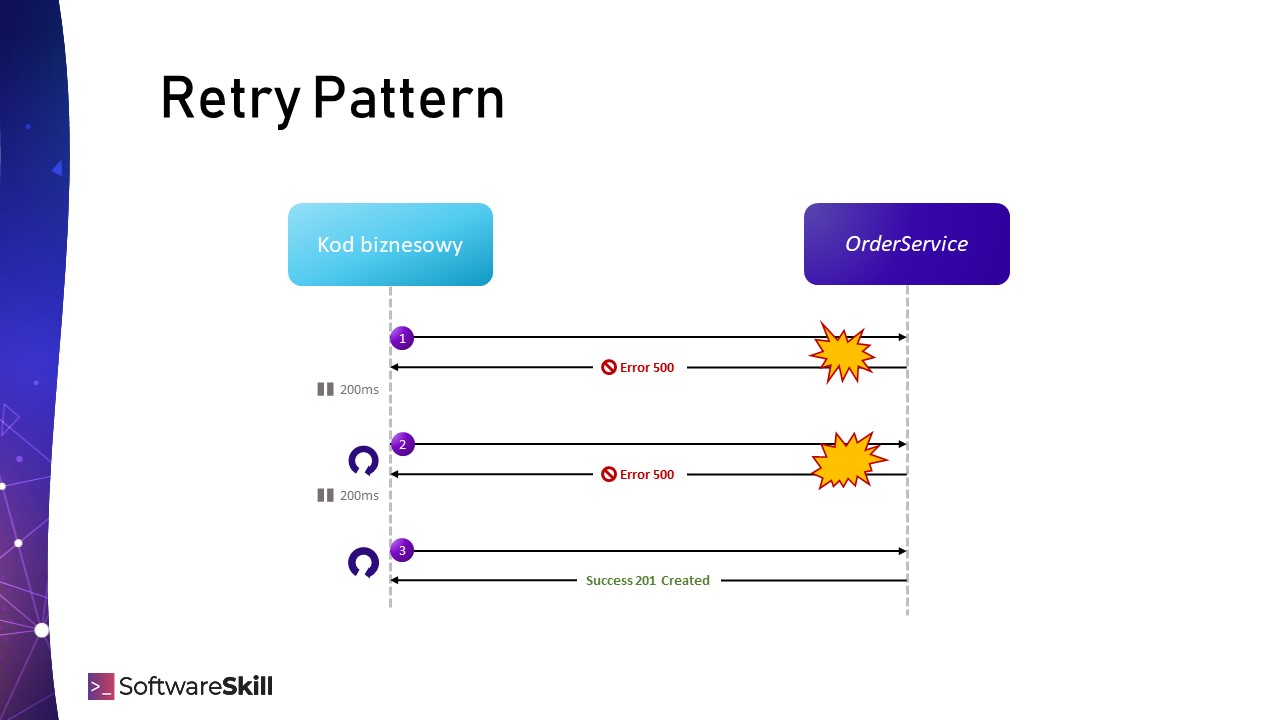
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
Ustawienia Retry Pattern nazywame są z reguły Retry Policy.
Co do zasady, wywołanie OrderService możemy udekorować w mechanizm ponawiania, na przykład za pomocą lambdy. Prezentuje to poniższy schemat:

Implementacja: resilience4j
Retry Pattern jest zaimplementowany m.in. w bibliotece resilience4j:
- to lekka, łatwa do użycia biblioteka Java
- stworzona pod Java 8 i wywołania lambd
- wspiera paradygmat programowania funkcyjnego dekorując funkcje
- implementuje wzorce: Circuit Breaker, Rate Limiter, Retry, Bulkhead
- gotowa integracja eksporu statystyk do micrometer.
Przykład udekorowania wywołania serwisu jako funkcja lambda:
RetryConfig config = RetryConfig.custom()
.maxAttempts(5)
.waitDuration(Duration.ofMillis(200))
.build();
Retry orderServiceRetry = Retry.of("OrderService", config);
var retryingOrderCreation = decorateCheckedSupplier(orderServiceRetry, orderService::createOrder());
Try.of(retryingOrderCreation)
.getOrElseThrow(() -> new IllegalStateException("Cannot place an order"));
Rodzaje opóźnień
Liniowe
Przed kolejną próbą można ustawić opóźnienie. Jedną ze strategii jest N prób ze stałym opóźnieniem T. W tym scenariuszu czas pomiędzy próbami nie zmienia się i jest stały, np. pięciokrotna próba co 200 ms.
Pozwala to na częste próbowanie ponowienia operacji, ale zbyt częste, agresywne z małym czasem opóźnienia może doprowadzić do uszkodzenia odpytywanego serwisu.

Wykładnicze (eksponencjalne)
Minusem stałego czasu opóźnienia może być zużycie wszystkich prób, podczas gdy problem się nie rozwiązuje. Można zastosować inny algorytm: wykładniczy. Oznacza on, że z każdą kolejną próbą czas opóźnienia będzie narastał. Pozwoli to określić liczbę prób oraz rozplanować je w czasie dając szansę na naprawienie się problemu.
Minusem jest to, że wraz z kolejnymi próbami, czas próbkowania zwiększa się i aplikacja staje się mniej reaktywna na ewentualną auto-naprawę środowiska w międzyczasie.
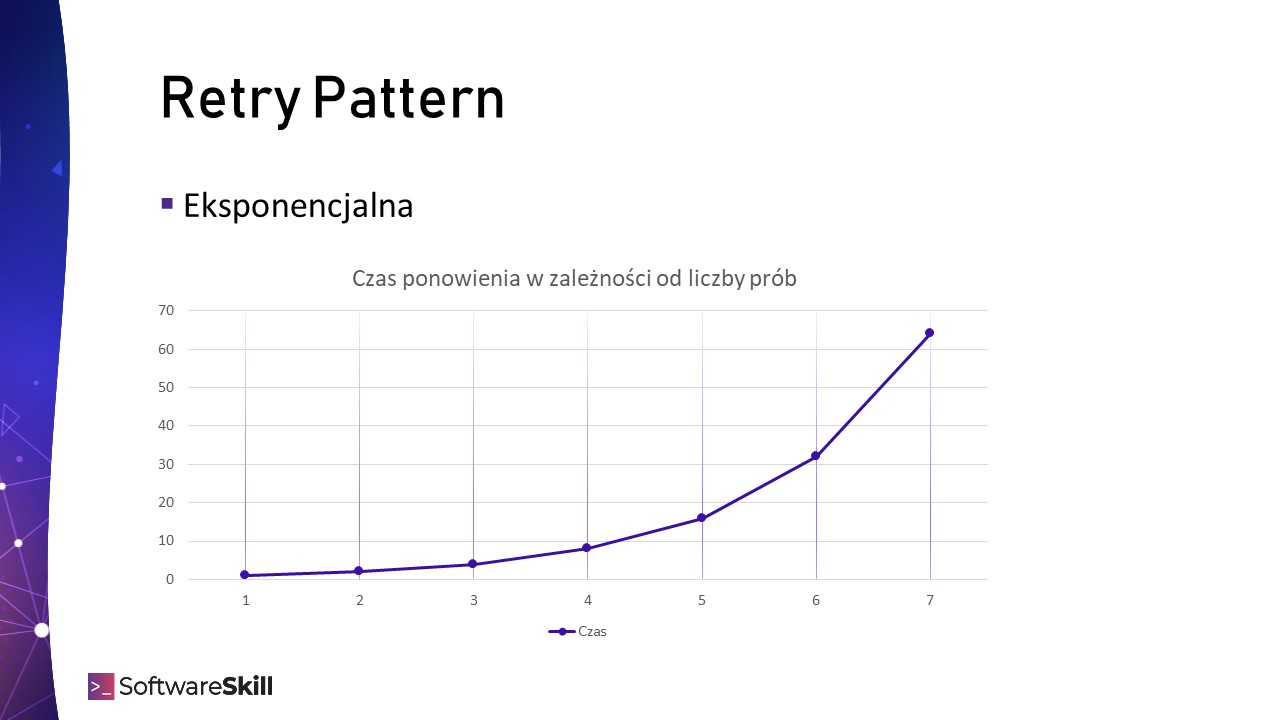
Poniższa przykładowa konfiguracja sprawi, że początkowe opóźnienie to 100ms i jest zwiększane 2x, także kolejne próby opóźnione zostaną o kolejno: 100ms, 200ms, 400ms, …
RetryConfig config = RetryConfig.custom()
.intervalFunction(IntervalFunction.ofExponentialBackoff(100, 2d))
.build();
Co musisz skonfigurować
Jakie operacje ponawiać
Warto zaznaczyć, że reakcją na niektóre błędy nie powinno być ponowienie, ponieważ nie poprawi to sytuacji. Mowa np. o błędach biznesowych i błędach walidacji (z serwii 4xx, np. 403 bad request). Dlatego możesz skonfigurować, jakiego typu wyjątki oraz treści odpowiedzi Retry ma obsługiwać:
RetryConfig config = RetryConfig.custom()
.maxAttempts(2)
.waitDuration(Duration.ofMillis(1000))
.retryOnResult(response -> response.getStatus() == 500)
.retryOnException(e -> e instanceof WebServiceException)
.retryExceptions(IOException.class, TimeoutException.class)
.ignoreExceptions(BusinessException.class, OtherBusinessException.class)
.build();
Rodzaje i parametry opóźnień
Jaki parametr opóźnienia przyjąć? Taki, który Twoim zdaniem, będzie odpowiedni, podczas którego problem może się rozwiązać. Warto:
- empirycznie to zbadać (lub z historii monitoringu),
- zadać pytanie, na jakie opóźnienie operacji w procesie biznesowym można pozwolić.
Retry Pattern + Circuit Breaker Pattern
Wspomniałem już, że Retry Pattern sprawdza się w przypadkach krótkotrwałych, samo naprawiających się awarii. Może jednak nastąpić dłuższa awaria, a ponawianie operacji tylko pogorszy sprawę generując dodatkowy ruch, który nie zostanie obsłużony. Wtedy warto zastosować wzorzec bezpiecznika, który obszernie opisuje w tym artykule.
Wzorzec Retry i Circuit Breaker warto zastosować razem poprzez kompozycję. Taka konfiguracja da nam dwie zalety:
- Krótkotrwałe awarie będą ponawiane przez Retry Pattern.
- Długotrwałe awarie natychmiast będą izolowane przez Circuir Breaker Pattern
(kolejne próby mogą być od razu omijane w przypadku rozwartego bezpiecznika).

Inne pytania
Czy ponawianie operacji jest bezpieczne?
Nie zawsze ponawianie operacji może wydawać się bezpieczne z biznesowego punktu widzenia. To, o czym jeszcze bym pomyślał, to czy złożenia ponowienia operacji jest idempotentne – czy wykonanie operacji nastąpi w przypadku tego samego żądania. Jeżeli nie, to, czy złożenie dwóch operacji nie wprowadzi niespójności w systemie (np. obniżenie linii kredytowej klientowi).
Wpis który czytasz to zaledwie fragment wiedzy zawartej w Programie szkoleniowym Java Developera od SoftwareSkill. Mamy do przekazania sporo usystematyzowanej wiedzy z zakresu kluczowych kompetencji i umiejętności Java Developera. Program składa się z kilku modułów w cotygodniowych dawkach wiedzy w formie video.
Podsumowanie
Retry Pattern to wzorzec integracyjny poprawiający odporność aplikacji polegający na ponawianiu operacji. Konfiguracja Retry powinna spełniać wymagania biznesowe. Czasem warto przerwać proces od razu, zamiast zmniejszać przepustowość aplikacji.
Zbyt częste, agresywne próby mogą nasilić problem, zaś zbyt wolne mogą zmniejszyć przepustowość systemu. Wartości opóźnienia warto jest dobrać empirycznie oraz po konsultacji z biznesem odnośnie do krytycznego czasu zakończenia procesu.
Podoba Ci się ten artykuł? Weź więcej.
Jeżeli uważasz ten materiał za wartościowy i chcesz więcej treści tego typu – nie przegap ich i otrzymuj je prosto na swoją skrzynkę. Nawiążmy kontakt.
Gdybyś potrzebował jeszcze więcej:
Jesteś Java Developerem?
Przejdź na wyższy poziom wiedzy
„Droga do Seniora” 🔥💪
Jesteś Team Leaderem? Masz zespół?
Podnieś efektywność i wiedzę swojego zespołu 👌
