W praktycznych projektach, kiedy komunikujemy się pomiędzy mikrousługami za pomocą kolejki – musimy uzgodnić w Teamie, w jaki sposób będziemy serializowali i deserializowali dane na kolejce. W jaki sposób zostanie rozwiązane wersjonowanie struktury komunikatów? To kluczowe pytania, z którymi musi zmierzyć się każdy zespół przy projektowaniu komunikacji pomiędzy mikroserwisami. O potencjalnych problemach możesz poczytać w artykule Jak uzyskać elastyczność mikroserwisów na poziomie komunikacji?
Ten artykuł jest kontynuacją serii o Apache Kafka. Na tapetę bierzemy Apache Avro, czyli bibliotekę do serializacji i deserializacji danych opartą na schemie definiującej strukturę komunikatu.
Aby zrozumieć informacje opisywane w artykule – powinieneś/aś wiedzieć czym jest i jak działa system kolejkowy Apache Kafka – w bardzo przystępny i szczegółowy sposób opisałem Apache Kafka w moim poprzednim artykule – Apache Kafka – wprowadzenie.
Problemy struktury komunikatu
Kafka przesyła dane w formacie binarnym. Sytuację prezentuje fotografia poniżej, gdzie producent po serializacji danych wysyła na kolejkę dane w postaci binarnej. Natomiast konsument po otrzymaniu danych w postaci binarnej musi je poddać procesowi deserializacji, aby być w stanie z nimi pracować.
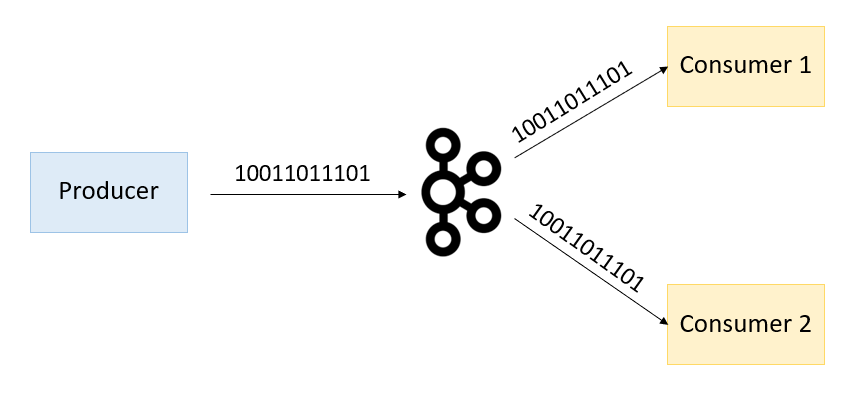
Ponadto sama Kafka nie dba o typ czy strukturę danych, jakie produkuje producent (nie jest to jej zadaniem). Zadaniem Kafki jest przesył danych, a nie dbanie o ich strukturę czy kompatybilność wsteczną. Rodzi to spory problem przy połączeniu producentów i konsumentów do tego samego topiku. Mianowicie, skoro Kafka nie dba o typ i strukturę danych – każdy z producentów może wysłać na topic co mu się jawnie podoba. Sytuację prezentuje fotografia poniżej, która uświadamia nam, że pod binarną postacią danych może kryć się dosłownie wszystko (dowolny format danych może zostać poddany serializacji do postaci binarnej – w końcu zera i jedynki to język komputera)!
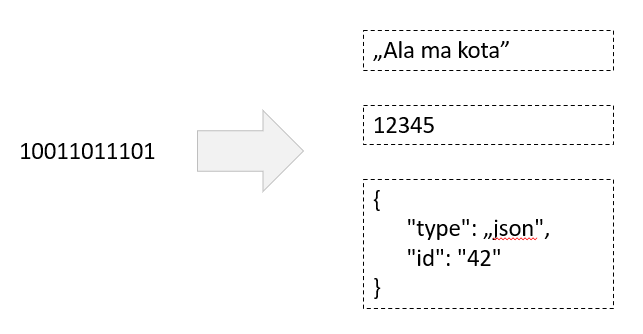
Skoro mamy problem ze strukturą danych – wprowadźmy standard JSON, który opisze nam model danych, który chcemy przesyłać po kolejce. JSON jesteśmy w stanie zserializować do postaci binarnej i w drugą stronę – zdeserializować z postaci binarnej do klasy Java. Czy to dobre rozwiązanie? Spójrzmy na fotografię poniżej.

Jak widzimy na rysunku powyżej – wprowadziliśmy strukturę danych opisującą nasz model, który przesyłamy po kolejce. Producent 1 przesyła pierwszą, prawidłową wersję komunikatu. Producent 2 zmienił typ pola „message” oraz zmienił format daty w polu „date” (no cóż, JSON nie weryfikuje typu konkretnego pola). Producent 3 zachował typ pól danych z JSON`a ale dodał kolejne pole, które nie było wcześniej znane. Jaki może mieć to wpływ na konsumenta? Spójrzmy na fotografię poniżej.

Producent produkuje inną strukturę danych niż oczekuje konsument. Co za tym idzie konsument nie jest w stanie prawidłowo prze-procesować wiadomości. Podsumujmy sobie te problemy, które wystąpiły podczas komunikacji pomiędzy producentem a konsumentem:
Piguła wiedzy o najlepszych praktykach testowania w Java
Pobierz za darmo książkę 100 stron o technikach testowania w Java

- Producent może wysyłać dane pod dowolną postacią – Kafka nie dba o typ i strukturę danych (jest to format binarny, pod którym może się kryć wszystko).
- Nie bardzo możemy użyć JSON, ponieważ nie gwarantuje nam on typowania danych oraz spójnej struktury komunikatu.
- Serializacja i deserializacja musi być lekkim procesem. Nie możemy za bardzo obciążać CPU.
- Jak to zwykle bywa, struktury komunikatów ewoluują w czasie. Dochodzą nowe pola, niektóre są usuwane. Jak sobie z tym poradzić, aby zachować kompatybilność wsteczną?
Potrzebowalibyśmy standardu, który jest prosty, ale jednocześnie umożliwi nam typowanie danych i możliwość ewolucji struktury komunikatu. Sama struktura komunikatu musiałaby posiadać dobrą dokumentację. Potrzebowalibyśmy coś takiego jak na fotografii poniżej.

Apache Avro jako rozwiązanie problemu
Apache Avro jest biblioteką do serializacji i deserializacji danych opartych o schemę, która reprezentuje strukturę danych. Schema jest zdefiniowane w JSON, co czyni ją bardzo prostą w tworzeniu. Avro jest niezależne od języka – tj. dane możesz serializować w Javie a deserializować w C#. Wylistujmy sobie kilka dodatkowych informacji o Apache Avro:
- Jest szybki (ponad 1 mln serializacji na sekundę).
- Jako wynik otrzymujemy dane w postaci binarnej.
- Dane są w pełni typowane.
- Serializacja i deserializacja oparta jest na schemacie opisanym w JSON.
- Schema opisująca strukturę komunikatu, przychodzi razem z komunikatem.
- Dane mogą być serialisowane / deserializowane przez różne języki.
- Avro posiada bogatą strukturę danych.
- Schema może ewaluować (dodawanie / usuwanie pól).
- Co warte zaznaczania Avro został wybrany przez Confluent Schema Registry jako jedyny wspierany format danych (o Schema Registry porozmawiamy w następnych artykułach z serii Kafka)
Typy danych w Avro
Jak wspomniałem wcześniej – Avro oferuje nam bogatą paletę typowania danych. Typy danych w Avro dzielimy na:
- Primitive Types
- Complex Types
Avro Primitive Types
Tutaj nie mamy żadnej filozofii. Avro obsługuje takie prymitywne typy jak:
- null
- boolean
- int
- long
- float
- double
- bytes
- string
Avro Schema Declaration
Przed omówieniem typów danych Complex Types warto jest wspomnieć o Schemie Avro, która ma za zadanie opisać strukturę komunikatu. Tak, aby można było go poddać procesowi serializacji i deserializacji wykorzystując opisywaną schemę. Spójrzmy na fotografię poniżej.

Na powyższej fotografii zaprezentowana jest przykładowa Schema Avro, która definiuje nam strukturę komunikatu. Schema jest zdefiniowana w formacie JSON, zapisana jest jako plik *.avsc. Avro oferuje kilka słów kluczowych, które opisują nam strukturę komunikatu:
Apache Kafka – wydajność vs. gwarancja dostarczenia wiadomości
Jak stworzyć piekielnie szybką albo maksymalnie bezpieczną wersję producenta oraz konsumenta.

- Type – to tzw. Complex Type – porozmawiamy o nim w następnym akapicie.
- Name – nazwa schemy.
- Namespace – pakietowanie.
- Doc – dokumentacja opisująca całą schemę lub konkretne pole.
- Aliases – jest to pole opcjonalne, definiuje inne nazwy schemy, pod którymi może być dostępna (więcej porozmawiamy przy omawianiu kompatybilności komunikacji)
- Fields – lista pól.
- Default – domyślna wartość pola.
Avro Complex Types
Avro oprócz typów prymitywnych oferuje te bardziej rozbudowane. W palecie Avro mamy dostępne: Enumy, Listy, Mapy, Unie, Inne schemy jako typy. Omówmy je po kolei.
Avro Enums
Jest to wartość enumerowana. Jako przykład można podać typ MessageType posiadający dwie wartości (INFO i CRITICAL). Przykład definicji enum`a w Avro zaprezentowany jest na fotografii poniżej.

Co warte zaznaczenia – zmiana wartości enuma przy kolejnej wersji schemy powoduje utratę danych i brak kompatybilności wstecznej.
Avro Arrays
Reprezentuje listę niezdefiniowanego rozmiaru o tym samym typie danych – np. lista emaili.

Avro Maps
Definiują listę <klucz, wartość>, gdzie klucze są stringami.

Avro Unions
Pozwalają na przechowywanie różnych typów w polu. Przykład: [„string”, „boolean”, „int”]. Jeśli zdefiniujemy wartość domyślną – musi być ona pierwszego typu z listy (w tym przypadku „string”). Stosuje się je przy definiowaniu opcjonalnych wartości.
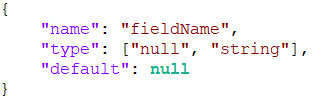
W tym przykładzie pole FieldName jest opcjonalne – może przyjmować wartość null, jeśli nie pojawi się w nim wartość typu string.
Aby użyć biblioteki Apache Avro w projekcie – w pierwszej kolejności powinniśmy dodać zależności mavenowe.
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-compiler</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.10.0</version>
</dependency>
W następnym korku w pom mavena, w sekcji build dodajemy plugin:
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.10.0</version>
<executions>
<execution>
<id>schemas</id>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
<goal>protocol</goal>
<goal>idl-protocol</goal>
</goals>
<configuration>
<sourceDirectory>${project.basedir}/src/main/resources/</sourceDirectory>
<outputDirectory>${project.basedir}/src/main/java/</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
Plugin ten ma za zadanie pobrać pliki schemy (*.avsc) z pakietu zdefiniowanego w sourceDirectory i wygenerować z nich klasy Javy do pakietu zdefiniowanego w outputDirectory. W kolejnym kroku powinniśmy zdefiniować samą schemę w formacie JSON. Schemę musimy zapisać z rozszerzeniem avsc. Poniżej zamieściłem trochę bardziej skomplikowany, praktyczny przykład.
{
"type": "record",
"name": "MessageEvent",
"namespace": "pl.softwareskill.event.message",
"fields": [
{
"name": "header",
"type": {
"type": "record",
"name": "HeaderRecord",
"namespace": "pl.softwareskill.event.header",
"fields": [
{
"name": "eventId",
"type": "string",
"doc": "Unique identifier of the event (UUID)"
},
{
"name": "traceId",
"type": "string",
"doc": "Originating event id. If the event is an origin then [eventId == traceId]"
},
{
"name": "createdAt",
"type": "long",
"doc": "Event time creation as the number of milliseconds since the epoch of 1970-01-01T00:00:00Z"
},
{
"name": "tags",
"type": [
"null",
{
"type": "map",
"values": "string"
}
],
"doc": "Additional [KEY=VALUE] tags for the event",
"default": null
}
]
}
},
{
"name": "EventData",
"type": {
"type": "record",
"name": "MessageRecord",
"namespace": "pl.softwareskill.event.message",
"fields": [
{
"name": "messageId",
"type": "string",
"doc": "Unique identifier of the message (UUID)"
},
{
"name": "priority",
"type": [
"null",
"int"
],
"doc": "Priority of message",
"default": null
},
{
"name": "params",
"type": {
"type": "array",
"items": {
"name": "Param",
"type": "record",
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "value",
"type": "string"
}
]
}
}
}
]
}
}
]
}
Po uruchomieniu komendy mvn clean install w katalogu zdefiniowanym w outputDirectory powinny pojawić się wygenerowane klasy (zgodnie z pakietowaniem zdefiniowanym przez pole namespace).
Jak widzimy na fotografii powyżej – Avro wygenerował 4 klasy – zgodnie z naszą definicją schemy, gdzie napisaliśmy:
......
"type": "record",
"name": "HeaderRecord",
"namespace": "pl.softwareskill.event.header"
......
"type": "record",
"name": "MessageEvent",
"namespace": "pl.softwareskill.event.message"
......
"type": "record",
"name": "MessageRecord",
"namespace": "pl.softwareskill.event.message"
......
"name": "Param",
"type": "record"
Poniżej widzimy, w jaki sposób możemy użyć klas. W pierwszym etapie używamy wygenerowanych builderów, aby zbudować modele. Model zawiera informacje o schemie.
//create record
HeaderRecord headerRecord = HeaderRecord.newBuilder().build();
MessageRecord messageRecord = MessageRecord.newBuilder().build();
MessageEvent messageEvent = MessageEvent.newBuilder()
.setHeader(headerRecord)
.setEventData(messageRecord)
.build();
//get schema
messageEvent.getSchema();
W następnym artykule z serii Apache Kafka pokażę Ci na praktycznym przykładzie w Java jak posługiwać się Avro. Jeśli nie chcesz, aby ominęły Cię artykuły – zapisz się do naszego newslettera – a pierwszy/pierwsza otrzymasz powiadomienie, prosto na swój adres email o nowym artykule,
Na koniec mam do Ciebie ogromną prośbę. Dla twórcy bardzo ważni są czytelnicy. Będę bardzo wdzięczny, jeśli podzielisz się niniejszym wpisem w kanałach social media. A jeśli jeszcze nie polubiłeś naszego FanPage na FaceBook – tu jest link https://www.facebook.com/softwareskill
Wpis który czytasz to zaledwie fragment wiedzy zawartej w Programie szkoleniowym Java Developera od SoftwareSkill. Mamy do przekazania sporo usystematyzowanej wiedzy z zakresu kluczowych kompetencji i umiejętności Java Developera. Program składa się z kilku modułów w cotygodniowych dawkach wiedzy w formie video.
Podsumowanie
Apache Avro to biblioteka służąca do serializacji i deserializacji danych. Proces ten oparty jest na schemie, która zdefiniowana jest w formacie JSON w plikach z rozszerzeniem *.avsc. Avro zapewnia pełne typowanie danych i ewolucję schemy – można dodawać i usuwać pola w czasie pracy. Apache Avro jest wykorzystywane jako jedyny format danych w Confluent Schema Registry. Avro jest powszechnie wykorzystywane jako standard komunikacji w systemach kolejkowych Apache Kafka.
Zakończenie
Apache Avro to biblioteka służąca do serializacji i deserializacji danych. Proces ten oparty jest na schemie, która zdefiniowana jest w formacie JSON w plikach z rozszerzeniem *.avsc.
W Avro typy danych dzielimy na: Primitive Types (null, boolean, int, long, float, double, bytes, string) i Complex Types (enum, list, map, unit, record)
Schema to plik JSON zapisany jako typ avsc. Schema definiuje strukturę komunikatu oraz określa typy pól.
Podoba Ci się ten artykuł? Weź więcej.
Jeżeli uważasz ten materiał za wartościowy i chcesz więcej treści tego typu – nie przegap ich i otrzymuj je prosto na swoją skrzynkę. Nawiążmy kontakt.
Gdybyś potrzebował jeszcze więcej:
Jesteś Java Developerem?
Przejdź na wyższy poziom wiedzy
„Droga do Seniora” 🔥💪
Jesteś Team Leaderem? Masz zespół?
Podnieś efektywność i wiedzę swojego zespołu 👌
