Wdrażaj na produkcję kilka razy dziennie za pomocą git’a. Continuous Delivery bez przeszkód.
Zastanawiało Cię kiedyś, które elementy w procesie pisania kodu i współpracy z innymi programistami wpływają na efektywność Twoich działań zmierzających do umieszczenia kodu na produkcji?
Oprócz analizy wymagań, głównym zajęciem programisty jest wytwarzanie kodu i kolaboracja z innymi programistami.
Miejscem tej kolaboracji jest repozytorium kodu w systemie kontroli wersji. To w nim umieszczamy efekt naszej pracy. Tam przeglądamy zmiany innych i łączymy z nimi nasze zmiany.
Na koniec, zmiany te uczestniczą w procesie Continuous Integration (CI), budowane są artefakty wdrożeniowe, a niektóre zwinne zespoły nawet używają procesu Continuous Delivery (CI/CD) do szybkiego i ciągłego wdrażania zmian na środowiska testowe i produkcyjne prosto z pipeline, w sposób w pełni zautomatyzowany.
Dwa popularne modele branchowania
Na efektywność naszej pracy wpływa między innymi to, jaki sposób zorganizujemy sobie model branch’owania w repozytorium. System kontroli wersji git daje pełną swobodę w podjęciu tego wyboru. W początkowej fazie popularyzacji git’a użytkownicy szukali schematów, a z czasem wyodrębniło się kilka modeli.
Istnieją dwa najbardziej popularne: gitflow i trunk-based development.
W gitflow programiści tworzą branch rozwojowy (develop) od głównej gałęzi i pracują nad zmianami w izolacji od głównej gałęzi. Trwają prace developerskie nad projektem lub zestawem zmian, a kiedy zmiany wydają się gotowe i przetestowane, mergeują go głównej gałęzi, która reprezentuje wersję produkcyjną.
W trunk-based development podejściu programiści aktywnie rozwijają produkt na głównej gałęzi (z nazwy trunk*). Wdrożenia następują prosto z głównej gałęzi. Co do zasady nie ma gałęzi, która reprezentuje produkcyjną wersję aplikacji – jest to jeden z commit’ów z głównej gałęzi.
* trunk to nazwa głównej gałęzi, w nomenklaturze git przyjęła się nazwa master lub main. W dalszej części posta będę stosował nazwę master lub główna gałąź.
Oba podejścia definiują, na której gałęzi skupia się główna aktywność programistów oraz jakie są rozmiary zmian. Mają różny narzut administracyjny nad branchami.
Z podejściem trunk-based development może pojawić się poczucie braku kontroli nad stabilną, w każdej chwili gotową do wdrożenia wersją kodu. W tym artykule pochylę się nad tymi aspektami.
W architekturze mikroserwisowej (lub serwisów średnich rozmiarów), w której baza kodu jest mała, a zmiany zespołu autonomiczne, gitflow może wprowadzić dodatkowy, niepotrzebny narzut.
Z moim zespołem stosujemy podejście trunk-based development i sprawdza się znakomicie. Dlatego postaram się jak najlepiej o nim opowiedzieć.
Czym jest trunk-based development
Trunk-based development to model branchownaia, w którym programiści umieszczają kod na głównej gałęzi (trunk). Najczęściej w nomenklaturze git’a nazwana jest main lub master.
Model pracy wygląda następująco:
Feature branch
Programiści tworzą krótko żyjące feature/* branch’e, na których opracowują zmiany. Zakres zmian jest na tyle mały, że prace można skończyć od kilku godzin, do maksymalnie kilku dni.
Na tych gałęziach nie przechowujemy całych projektów, a drobne zmiany kontrybuujące do nich. Jedną agile’ową historyjkę można podzielić na przykład na kilka drobniejszych zmian.

Zmiany są integrowane często. Może zdarzyć się, że zmiana nad którą pracujemy nie jest w pełni gotowa, dlatego ważne jest, aby swoimi kontrybucjami nie blokować innych, na przykład:
- nie wprowadzać nieprzemyślanych zmian,
- wprowadzać zmiany w taki sposób, aby było możliwe wydanie oprogramowania z głównej gałęzi.
Kluczowy w tym podejściu jest zestaw dobrych testów, który w procesie CI przed złączeniem zmian uruchomi je i da nam pewność, że nie wprowadziliśmy regresji.
Piguła wiedzy o najlepszych praktykach testowania w Java
Pobierz za darmo książkę 100 stron o technikach testowania w Java

Przez myśl przemknęło Ci zapewne, że pewne zmiany po prostu nie mogą wyjść na produkcję. Na przykład: w momencie, kiedy jesteśmy w połowie implementacji projektu albo nawet mniejszego feature’a, wypuszczanie oprogramowania może być problematyczne.
O technikach, które to ułatwiają wspomnę w dalszej części posta.
Stabilizacyjny release branch (opcjonalnie)
Może zdarzyć się sytuacja, w której potrzebujemy odrobiny stabilizacji stanu repozytorium, które chcemy wypuścić na produkcję.
Dajmy na to, znaczna część jest gotowa i już prawie możemy wydać wersję, ale wiemy, że w tym samym sprincie za moment szykują się większe dalsze zmiany. Albo wydajemy oprogramowanie wolniej, niż co commit, na przykład tygodniowo i zbliżamy się do zamknięcia zakresu, ale trwa dalszy rozwój produktu.
Wtedy możemy utworzyć release/* branch z nazwą kolejnej wersji, na którym „zamrozimy” na chwilę stan i stamtąd wydamy oprogramowanie (zamiast z trunk).
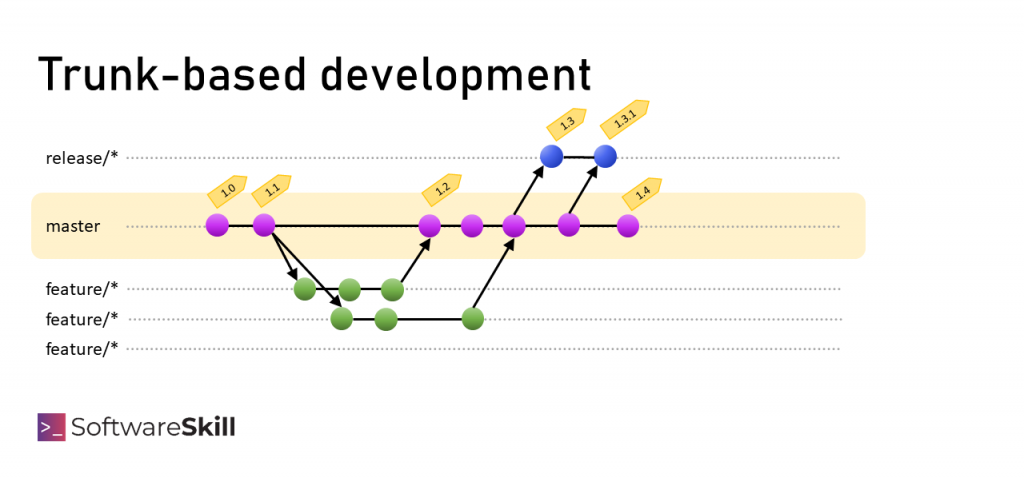
To całkowicie normalny i lekki proces, który nie angażuje dużo administracyjnej pracy w zarządzanie branch’ami oraz nie wprowadza procesu „feature-freeze” blokując dalszy rozwój.
Patch (hotfix)
Zdarza się, że trzeba wprowadzić poprawkę w kodzie produkcyjnym. Wprowadzamy ją na zasadzie drobnej zmiany odbijając feature/* branch.
W podejściu trunk-based development integrujemy bardzo często i nie ma długo żyjących branchów, większość kodu jest na produkcji, więc wprowadzenie jej powinno być stosunkowo proste.
Mamy poprawkowy commit. Trzeba go teraz umieścić w kodzie produkcyjnym. Mamy następujące opcje:
Opcja #1: Zostawiamy poprawkę na głównej gałęzi i jeżeli czujemy się komfortowo z innymi zmianami – po prostu robimy wdrożenie. To podejście nosi nazwę „fix-forward”, czyli naprawimy wprzód wprowadzając przy okazji nowe zmiany, nie cofamy się.
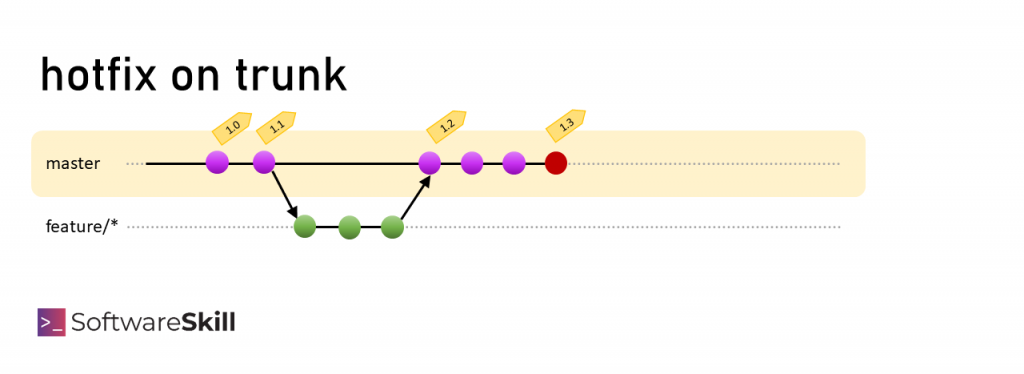
Jeżeli jednak ze zmianami od ostatniego wdrożenia nie czujemy się w pełni komfortowo to:
Opcja #2: Jeżeli został wcześniej stworzony release-branch, możemy go wykorzystać i przenieść na niego poprawkę (cherry-pick).
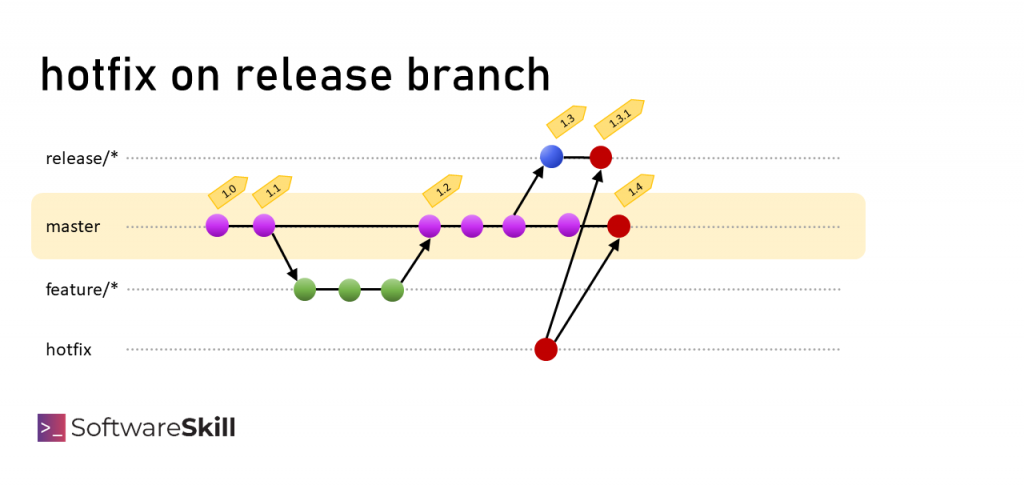
Opcja #3: Jeżeli release branch nie został wcześniej stworzony to można stworzyć nowy release/* branch od poprzedniego commit’a, który jest już od jakiegoś czasu na produkcji. Następnie wykonać cherry-pick i wydać tę wersję.
Jak widzisz, nie ma wielu branch’ów, więc wybór jest w miarę prosty.
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
Trunk based development vs gitflow
W gitflow programiści pracują na branch’u rozwojowym (develop) i pracują nad zestawem zmian w izolacji. Główna gałąź, która reprezentuje produkcyjny kod, nie zmienia się z każdą wprowadzaną zmianą.
Trwają aktywne prace developerskie, a kiedy zmiany wydają się gotowe i przetestowane, są merge’owane go głównej gałęzi.
W międzyczasie od branch’a develop, na którym trwają aktywne prace może zostać stworzony branch release/*, aby ustabilizować zmiany. Wtedy poprawki trafiają na branch develop oraz przenoszone są release/*.
W istocie na sam koniec kod trafia na główny branch, z brancha develop lub release. Główny branch reprezentuje wersję produkcyjną.
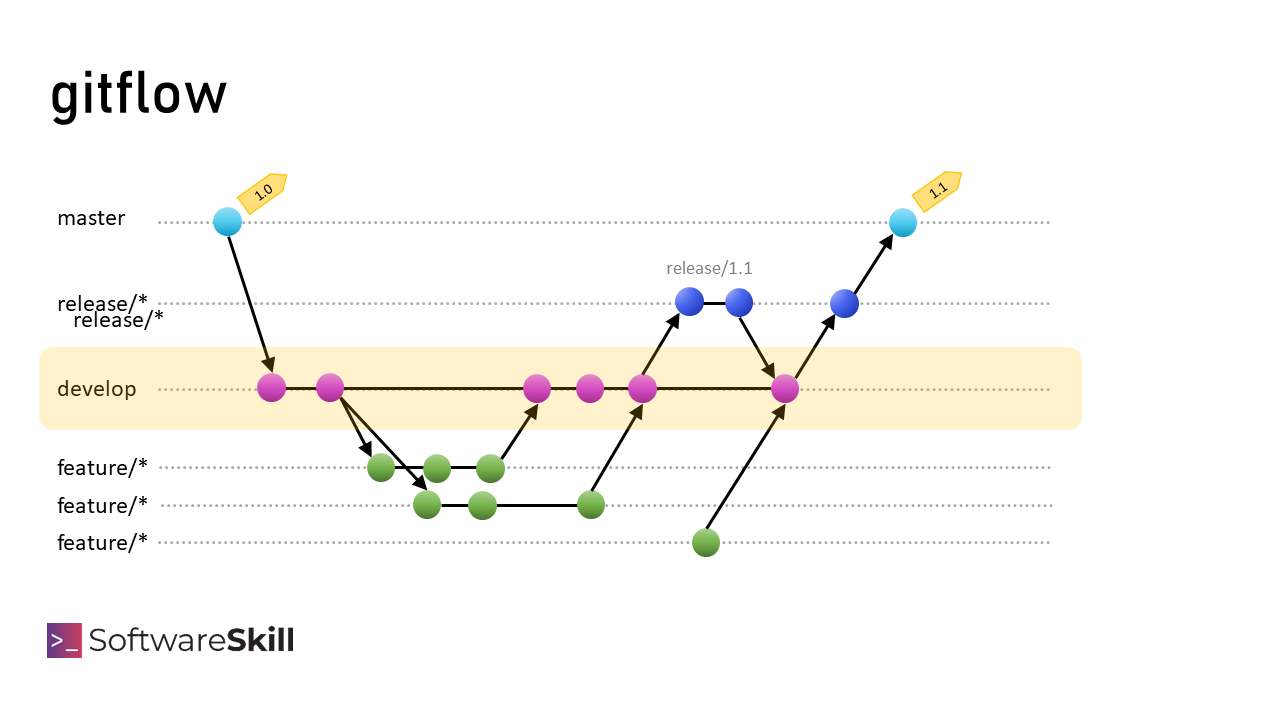
Zasadnicza różnica polega na tym, w którym miejscu deweloperzy są aktywni oraz jak duże zmiany trafiają do głównej gałęzi.
Główna gałąź jest miejscem stabilizacji kodu produkcyjnego oddzielonego od gałęzi, na której prowadzona jest bieżąca aktywność rozwojowa.
Istnieje narzut administracyjny w postaci merge’owania zmian:
- w momencie stabilizacji i uruchomieniu release/* branch: z develop na release branch (tzw. dodawanie zmian na release)
- w momencie wdrożenia release branch na produkcję, do:
- mastera
- develop
- wszystkich innych aktywnych release branch
- hotfix
- na master
- na develop
- na wszystkie release branches
Ponieważ branch develop to długo żyjący branch, a mergeowanie zmian wchodzących na produkcję to kilka kroków, możliwe są pomyłki i późniejsze duże konflikty w kodzie.
Kiedy w jednym z zespołów stosowaliśmy ten model, nie raz zdarzyło się pominięcie mergeowania gałęzi release do master, develop lub do innych gałęzi release. Innym pytaniem było – kto miałby to robić – koordynator wdrożenia? Powstawały narzędzia usprawniające proces i sprawdzające stan repozytorium.
Wszystko jest kwestią dyscypliny. Chciałem jednak podkreślić dodatkowy narzut.
Zalety podejścia trunk-based development
Szybka i bieżąca integracja całego kodu
W podejściu trunk-based development zmiany w sposób ciągły są złączane z główną gałęzią. Dodanie testów automatycznych i metryk pokrycia kodu testami do procesu Continueous Integration sprawia, że napływające zmiany mają zapewnioną odpowiednią jakość.
Brak jest długo żyjących feature branch’ów do utrzymania i rozwiązywania konfliktów. Deweloperzy również lokalnie pracują na małych pojawiających się w międzyczasie zmianach.
Kolejne wersje oprogramowania powstają w dużej części z głównej gałęzi, a wersje na środowiskach mogą być dowolnie wdrażane. Na przykład, aby wdrożyć coś na produkcję nie trzeba przerzucać zmian pomiędzy branch’ami – jest to po prostu któraś wersja w historii zmian.
Ciągłe i mniejsze Code Review
Małe zmiany są łatwiejsze do przejrzenia w procesie Code Review. Zmienia się kilka lub kilkanaście plików. Minimalizujemy efekt przeciążenia kognitywnego koncentrując się na jednej, małej zmianie. W ten sposób łatwiej skupić się na kodzie. Wychwycić błędy, poprawić czytelność kodu albo zaproponować nowe przypadki testowe.
Oprócz przeciążenia kognitywnego istnieje pewien koszt związany ze zmianą kontekstu (context-switching). Dlatego członkowie zespołu, zanim zabiorą się za pracę głęboką, lub mają przerwę pomiędzy małymi zadaniami, powinni skupić się na Code Review przed podjęciem nowego zadania lub aktywności.
Jedna baza kodu do testowania
Istnieje jedna baza kodu oprogramowania, które testujemy i wdrażamy na produkcję. Ewentualne funkcjonalności włączamy lub wyłączamy za pomocą Feature Toggles lub Feature Flags, ale wciąż jest jedna baza kodu sterowana ustawieniami.
Nie przełączamy różnych wariantów aplikacji, które są umieszczone na różnych release branch’ach (jedna gałąź i wersja ma dane zmiany, inna jeszcze nie ma). Minimalizujemy liczbę środowisk testowych, koncentrując się na kilku (lub jednym), ale za to bardzo stabilnych.
Możliwość wprowadzenia procesu CI/CD
W modelu trunk-based development jest dużo łatwiej wprowadzić szybki cykl wydawania oprogramowania w procesie Continuous Integration (CI) i Continuous Deployment (CD).
Po złączeniu zmian do głównej gałęzi, uruchomi się zestaw testów automatycznych i testów zapewniających parametry jakościowe (np. code quality, code coverage). Następnie w procesie CD można wdrożyć aplikację na środowisko testowe. Idąc dalej na środowisko produkcyjne:
- Można zdecydować się na manualną decyzję i kliknięcie przycisku, który uruchomi dalej w pełni automatyczny proces wdrożeniowy.
- Niektóre dojrzałe zespoły decydują się nawet, że po zapewnieniu czynnika jakościowego, zmiany od razu po złączaniu z trunk trafiają na produkcję. W tym wypadku musimy mieć bardzo łatwy i szybki proces wycofywania zmian.
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
Wyzwania
Trunk-based development powoduje, że wprowadzane zmiany mogą być w każdej chwili wdrożone na produkcję.
W gitflow funkcję stabilizacyjną pełniły release branche oraz master. To w tym momencie podejmowaliśmy decyzję, że paczka zmian ma być wdrożona.
Szukamy więc mechanizmów stabilizacji, co konkretnie pojawi się na produkcji i w jakim tempie.
Stabilizacja kodu
Mogą istnieć momenty przed wdrożeniem, w których chcemy ustabilizować wdrażany kod. W tym celu tworzymy release/* branch’e z głównej gałęzi. Ewentualne zmiany w wersji nanosimy prosto na trunk oraz cherry-pick na release branch.
Podobnie z hotfixami – możemy wybrać strategię kontynuacji gałęzi trunk lub wrócić do poprzedniego stanu projektu i zaaplikować patch wstecz tworząc nową wersję.
Technika nosi nazwę Branch for Release.
Feature Toggles, Feature Flags
Zmiany nad którymi aktualnie pracujemy możemy umieszczać w nieaktywnych blokach kodu. Są to po prostu if-y. Następnie możemy je włączać dynamicznie za pomocą Feature-toggles lub Feature-flags.
Aplikacja podczas swojego działania (runtime) lub podczas wdrożenia (deployment-time) może przyjmować w swojej konfiguracji parametr udostępniając daną funkcjonalność lub nie.
Sposób kontroli wywoływania kodu zmienia się w stosunku do gitlow z fizycznego umieszczenia go na innym branchu w systemie kontroli wersji, do wprowadzenia nieaktywnej, sterowanej podczas działania aplikacji sekcji kodu na głównym branchu. Tym sposobem możemy pozbyć się długo żyjących feature branchów.
Przykład: implementowana jest nowa funkcjonalność. Dopóki nie zostanie ona w pełni ukończona, możemy na środowisku produkcyjnym całkowicie ją wyłączyć. Nadal możemy pozostawić tę funkcjonalność aktywną na środowisku testowym.
Poniżej przykład runtime feature-toggle z biblioteki Togglz:
public void someBusinessMethod() {
if(Features.FEATURE_ONE.isActive()) {
// do new exciting stuff here
}
// ...
}
Poniżej przykład deployment-time feature-flag jako profil Spring:
@Configuration
public class SomeFuncConfig {
@Bean
SomeFunc someFunc(@Value("${features.featureOne.enabled}" boolean featureOneEnabled) {
return new SomeFunc(featureOneEnabled);
}
}
A następnie w konfiguracji:
application.properties
features:
featureOne:
enabled: true
featureXX:
enabled: true
Ważnym jest, aby:
- Przy wprowadzeniu Feature Toggles zapewnić testy na obie ścieżki w procesie – kod jest włączony oraz kod jest wyłączony.
- Testowanie dwóch ścieżek wprowadza dodatkowy koszt wykonaniu testów oraz dodatkowy kod, dlatego z czasem Feature Toggles należy usuwać.
Branch by Abstraction
Istnieje scenariusz, w którym chcemy zastąpić funkcjonalność inną implementacją. Jednocześnie nie chcemy blokować innych członków zespołu i wprowadzać zależności, podczas gdy nasza implementacja zajmie chwilę dłużej. Wyróżniamy dwa fragmenty kodu: istniejący do zastąpienia oraz nowy do wprowadzenia.
W wywołaniu kodu do zastąpienia możemy wprowadzić abstrakcję (np. interfejs) oraz zapewnić bieżącą implementację. Taką zmianę możemy wprowadzić do repozytorium, ponieważ nie wprowadza zmian, a inni członkowie zespołu od niej nie zależą. Wybór implementacji możemy uzależnić od Feature Toggle.
Technika nosi nazwę Branch by Abstraction.
- Wprowadzamy abstrakcję i bieżącą implementację. Bieżąca implementacja jest włączona.
- Pracujemy nad nową implementacją. Możemy to robić dłuższy czas. Zapewniamy testy na wariant z bieżącą implementacją i nową.
- Gdy funkcjonalność jest gotowa, możemy włączyć nową implementację jako domyślną.
- Usuwamy starą implementację.
- Usuwamy abstrakcję.
Przykład z parametryzacją beanów w Spring włączający bieżącą lub nową implementację:
@Configuration
public class SomeFuncConfig {
@Bean
@ConditionalOnProperty(name = "features.featureOne.enabled", matchIfMissing = true)
public SomeFunc defaultSomeFunc() {
return new SomeFunc();
}
@Bean
@ConditionalOnProperty(name = "features.featureOne.enabled")
public SomeFunc anotherSomeFunc() {
return new AnotherSomeFunc();
}
}
Podsumowanie
Porównałem podejścia trunk-based development i gitflow.
Główną różnicą jest to, na jakiej gałęzi skupia się główna aktywność członków zespołu oraz jak duże zmiany są łączone do gałęzi reprezentującej produkcyjny stan systemu.
Trunk-based development daje możliwość wprowadzenia procesu CI/CD i przyspieszenia wdrożeń – nie trzeba bowiem zarządzać wieloma branch’ami.
Mimo potencjalnych wyzwań ze stabilnością kodu na głównej gałęzi, dostępne są techniki stabilizacyjne takie jak Feature Toggles, Branch by Abstraction, Branch for Release czy Hotfix.
Podoba Ci się ten artykuł? Weź więcej.
Jeżeli uważasz ten materiał za wartościowy i chcesz więcej treści tego typu – nie przegap ich i otrzymuj je prosto na swoją skrzynkę. Nawiążmy kontakt.
Czytaj więcej
- trunkbaseddevelopment.com
- atlassian.com/continuous-delivery/continuous-integration/trunk-based-development
- cloud.google.com/architecture/devops/devops-tech-trunk-based-development
FAQ
gitflow to model tworzenia gałęzi w repozytorium kodu, w której tworzony jest branch rozwojowy (develop) od głównej gałęzi, a praca nad zmianami odbywa się w izoalcji. Trwają prace rozwojowe nad projektem lub zestawem zmian, a kiedy zmiany są gotowe i przetestowane, umieszczane są w głównej gałęzi, która reprezentuje wersję produkcyjną.
Trunk-based development to model tworzenia gałęzi w repozytorium kodu, w którym programiści aktywnie rozwijają produkt na jednej głównej gałęzi. Wdrożenia następują prosto z głównej gałęzi.
Feature Toggle to przełącznik (ustawienie), które włącza lub wyłącza dany fragment funkcjonalności w aplikacji. Dzięki temu możliwe jest sterowanie, jakie funkcjonalności są dostępne dla użytkownika.
