Apache Kafka to bardzo rozbudowany system umożliwiający dostosowanie się pod praktycznie każdą potrzebę biznesową. Jeśli chcemy wysokiej przepustowości i zezwalamy na utratę komunikatów (np. logi, metryki) – proszę bardzo – Kafka przygotowuje dla nas ustawienia producentów. Jeśli zależy nam na jak największej spójności danych (np. przelewy, geolokalizacja) – proszę bardzo mamy inne ustawienia. W dzisiejszym artykule na tapetę weźmiemy producenta w systemie Apache Kafka.
Z tego artykułu dowiesz się:
- Z jakich komponentów składa się producent wiadomości
- Co to jest ProducerRecord, Serializer, Partitioner
- Po wystąpieniu jakich błędów Kafka automatycznie ponawia wysyłkę
- Jakie błędy muszą zostać manualnie obsłużone przez programistę
- Jak wysłać wiadomość do Kafki w Java
- Jak są typy wysyłania wiadomości (fire and forget, synchronous send oraz asynchronous send)
- Jakie są obowiązkowe ustawienia producenta
- Co daje nam ustawienie klucza wiadomości, a czym ryzykujemy, jeśli go nie ustawimy
Ten artykuł jest kontynuacją serii artykułów o Apache Kafka. Aby zrozumieć zagadnienia omawiane w tym wpisie, powinieneś/aś rozumieć czym jest Apache Kafka i w jaki sposób działa – w poprzednim wpisie z serii systemów kolejkowych opisałem to w bardzo przystępny i szczegółowy sposób. Zapraszam serdecznie do zapoznania się z poprzednikiem tego artykułu Apache Kafka – wprowadzenie
Apache Kafka – wydajność vs. gwarancja dostarczenia wiadomości
Jak stworzyć piekielnie szybką albo maksymalnie bezpieczną wersję producenta oraz konsumenta.

Komponenty producenta
API producenta Kafki dla programisty jest przeźroczyste. Cały poziom skomplikowania jest ukryty w implementacji Kafki, która na zewnątrz wystawia proste API, dzięki któremu możemy wysyłać wiadomości do brokerów. Warto jest jednak wiedzieć, z jakich komponentów składa się producent Kafki, aby lepiej zrozumieć cały proces oraz obsługę błędów wysyłki. Spójrzmy na poniższą fotografię prezentującą jakie komponenty biorą udział w wysyłce wiadomości (jest to uproszczony schemat).
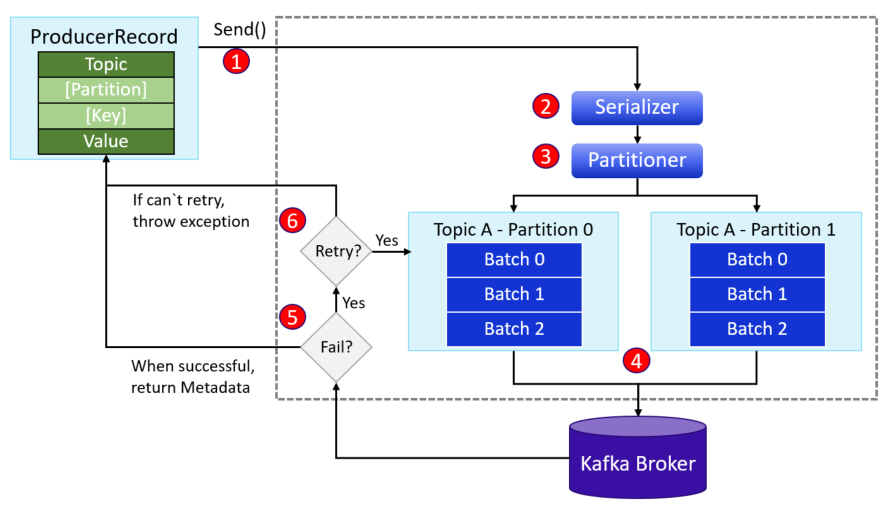
ProducerRecord
Jest to klasa, która zawiera w sobie parametry (pola), które wysyłamy do klastra Kafki. Kolorem ciemno-zielonym zaznaczyłem pola obowiązkowe, są to Topic oraz Value. Pierwszy z nich (Topic) to nic innego jak słowna nazwa topiku, na który chcemy wysłać wiadomość. Value to z kolei wartość komunikatu. O typach tych pól porozmawiamy za chwilkę.
Nieobowiązkowe pola to Partition oraz Key. Pierwsze z nich (Partition) wskazuje na numer partycji, na którą chcemy zapisać wiadomość. Key to klucz, który służy do identyfikacji „grupy” wiadomości.
Po stworzeniu obiektu ProducerRecord następuje przekazanie wiadomości do serializacji, tak aby zmienić obiekt na ciąg bajtów, obsługiwanych przez sieć (pkt 1 na fotografii).
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
Serializer
Serializer to prosta funkcjonalność, która odpowiada za serializację wiadomości wysyłanych do klastra Kafki (nr 2 na fotografii).
Partitioner
Partitioner (nr 3 na fotografii) pełni kilka ważnych funkcji. Po pierwsze, jeśli w klasie ProducerRecord podamy nieobowiązkowy parametr Partition – nie robi on nic innego jak zwrócenie danych partycji, na którą ma być odłożony komunikat oraz odkłada wiadomość na szczyt kolejki (batch), którą podejmie osobny wątek i hurtowo wyśle batch wiadomości do brokera Kafki (pkt nr 4).
Jeśli nie podamy parametru, wskazującego jawnie na nr partycji, do której chcemy pisać – Partitioner przeprowadzi „load balancing” i postara się po równo rozdzielić komunikaty na dostępne partycje w ramach topika (tracimy kolejność komunikacji)
Moim zdaniem najistotniejszym ustawieniem ProducerRecord jest klucz wiadomości (Key). Jeśli nie podamy klucza, który jest z resztą nieobowiązkowym polem – Partitioner znów skorzysta z „load balancingu” i postara się porozdzielać komunikację w ten sposób, aby każda z partycji, składających się na topik miała porównywalną ilość danych.
Co istotne brak podania numeru partycji czy klucza oznacza losowość przy odczycie komunikatów przez konsumenta – Kafka nie gwarantuje nam zachowania kolejności komunikacji, jeśli dane dotyczące konkretnego zdarzenia będą porozrzucane po różnych partycjach. Wyobraźmy sobie, że klucz to id numeru konta, z którego wykonywane są przelewy. I teraz mamy taką sytuację. Na koncie mamy 2000 zł. Pierwsza wiadomość to przelew przychodzący na kwotę 1000 zł. Druga wiadomość to przelew wychodzący na kwotę 3000 zł.
- stan początkowy = konto zasilone środkami w wysokości 2000 zł
- pierwsza przychodzi wiadomość o przelewie przychodzącym na 1000 zł
- stan pośredni = saldo 3000zł
- przychodzi kolejny komunikat na wypłatę środków 3000 zł – wszystko jest zgodnie z myślą
Spójrzmy co się stanie, jeśli kolejność komunikatów nie zostanie zachowana (brak ustawienia klucza wiadomości)
- stan początkowy = konto zasilone środkami w wysokości 2000 zł
- przychodzi komunikat o wypłacie środków w wysokości 3000 zł – użytkownik dostaje błąd, że ma nie wystarczającą ilość środków na koncie (a przecież przed chwilą zasilił konto dodatkowym 1000 zł, żeby mieć 3000 zł na wypłatę!)
Jeśli dostarczymy klucz, wówczas Partitioner poszuka, na jakiej partycji odkładane są wiadomości o tym samym kluczu i zwróci dane tej partycji, aby odłożyć wiadomość w buforze (batch) przypisanym do konkretnej partycji, który znów zostanie wysłany za pomocą drugiego wątku Kafki prosto do brokera.
Kafka Broker
Broker Kafki, po otrzymaniu porcji wiadomości może potwierdzić prawidłowość procesu i zwrócić Metadane, które zawierają m.in. takie dane jak:
- Nr partycji, na której został zapisany komunikat
- Offset zapisanego komunikatu
Jeśli coś pójdzie nie tak – Kafka może ponowić wysłanie wiadomości. Ale na jakiej podstawie producent wie, czy ponowić wysyłkę, czy nie? Otóż Kafka zwraca 2 główne rodzaje błędów do producenta wiadomości, jeśli coś pójdzie nie tak:
- Błędy, po których producent automatycznie może ponowić wysyłkę, bez wiedzy programisty. To takie błędy jak chwilowa niedostępność leadera partycji (np. podczas rebalancingu leaderem partycji zostaje mianowana replika, a leader jest chwilowo niedostępny). Kolejnymi błędami, po których można automatycznie ponowić wysyłkę są np. chwilowe problemy z siecią.
- Błędy, z którymi producent nie poradzi sobie automatycznie. Jeśli wystąpi błąd serializacji – mało prawdopodobne jest, że ponowienie serializacji nie wygeneruje tego samego błędu. W takim przypadku Broker Kafki wyrzuca błąd wprost do producenta wiadomości. I w naszej gestii jest odpowiednie zareagowanie na wystąpienie błędu.
Obowiązkowe parametry producenta
Każdego producenta trzeba skonfigurować tak, aby była możliwość podłączenia z klastrem Kafki oraz pisania do konkretnego topiku. Omówmy je po kolei.
bootstrap.servers
To lista [host:port] definiująca brokery do inicjalnego połączenia z klastrem Kafki. Nie musi to być pełna lista wszystkich brokerów (w końcu API jest przeźroczyste i producent nie musi zdawać sobie świadomości ze struktury klastra). Warto jest jednak dać kilka brokerów, jeśli jeden z nich ulegnie awarii, producent spróbuje się połączyć z kolejnym z listy.
key.serializer
Nazwa klasy użyta jako serializer danych. Kafka przyjmuje tablicę bajtów, jednak w kodzie chcielibyśmy operować wygodnymi obiektami. Ten parametr wskazuje na klasę serializującą dane do postaci binarnej. Klasa ta musi implementować interfejs org.apache.kafka.common.serialization.Serializer. Można pisać własne serializatory jednak Kafka oferuje już gotowe np.: StringSerializer, and IntegerSerializer.
value.serializer
Podobnie jak key.serializer – klasa serializująca wartość wiadomość do postaci binarnej.
Zobaczmy jak może wyglądać konfiguracja obowiązkowych parametrów w Java.
Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers","broker1:9092,broker2:9092");
kafkaProps.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
kafkaProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer & ProducerRecord
Kiedy mamy już parametry producenta możemy przystąpić do stworzenia instancji klasy KafkaProducer, a następnie utworzyć obiekt ProducerRecord, który będzie reprezentował naszą wiadomość.
KafkaProducer<String, String> producer = new KafkaProducer<>(kafkaProps);
ProducerRecord<String, String> record =
new ProducerRecord<>("topic", "key", "value");
W tym prostym przykładzie zakładamy, że klucz oraz wartość naszej wiadomości są typu String (tak skonfigurowaliśmy serializatory – key.serializer oraz value.serializer)
Metody wysyłania wiadomości
Przy metodach wysyłania wiadomości robi się troszkę bardziej skomplikowanie, ponieważ w zależności od założeń biznesowych naszej aplikacji – Kafka oferuje aż 3 typy wysyłki wiadomości. Omówmy je pokolei.
Fire and forget
Czyli „wyślij i zapomnij” – nie przejmujemy się tym czy klaster Kafki poprawnie odebrał wiadomość. Bardzo wysoka przepustowość i niskie opóźnienia, ale wiadomości mogą zostać utracone. Ta metoda może być używana, gdy dopuszczamy możliwość straty wiadomości. Zwykle niestosowana na środowiskach produkcyjnych (chyba że chcemy rozsyłać logi, metryki – gdzie utrata pojedynczych komunikatów nie ma większego znaczenia). Wiadomości zostają odkładane do buforu, aby zostać wysłane do brokera (dokładnie tak jak na schemacie we wstępie). Zwiększając czas bezczynności przed wysłaniem buforu wiadomości (parametr linger.ms) możemy znacząco podnieść wydajność wysyłki (więcej wiadomości zabierze się podczas jednego requestu, ponieważ zwiększamy czas napełniania buforu przed wysyłką)
try {
producer.send(record);
} catch (Exception e) {
log.error("Error while sending", e);
}
Chociaż ignorujemy błędy, które mogą wystąpić podczas wysyłania wiadomości do brokerów lub w samych borkerach to mamy możliwość przechwycenia błędów przed wysłaniem wiadomości np.:
- SerializationException – błąd serializacji wiadomości.
- TimeoutException – pełny bufor.
- InterruptException – wątek wysyłający został przerwany.
Błędy, których pojawienie się może trigerować automatyczną re-wysyłkę (np. problemy z siecią) są dalej obsługiwane przez Kafkę.
Synchronous send
Czyli synchroniczna wysyłka – wysyłamy wiadomość za pomocą metody send() i oczekujemy na obiekt Feature – zupełnie tak jak poprzednio, tyle że używamy metody get(), żeby poczekać na Feature i zobaczyć czy wysyłka przebiegła prawidłowo, czy nie. Warto jest dodać, że czekanie na odpowiedź blokuje aplikacje (synchroniczna wysyłka). Jeśli klaster Kafki potwierdzi otrzymanie rekordu – zwróci obiekt RecordMetadata. Jeśli rekord nie zostanie pomyślnie wysłany do klastra Kafki – otrzymamy błąd. Niektóre z błędów zwracanych do producenta jak np. błąd serializacji skutkują raczej brakiem możliwości ponowienia wysyłki – bo w końcu, jakie jest prawdopodobieństwo, że ponowna serializacja nie zwróci tego samego błędu. Jednak niektóre z błędów jak np. niewystarczająca liczba replik (chwilowa awaria repliki partycji, która pewnie za kilka sekund wróci do świata żywych) może zostać ponowiona za pomocą wzorca projektowego Retry Pattern, który Piotrek opisywał w tym artykule https://softwareskill.pl/retry-pattern.
try {
Future<RecordMetadata> future = producer.send(record);
// flush producer queue to spare queuing time
producer.flush();
// throw error when kafka is unreachable
future.get(10, TimeUnit.SECONDS);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
log.error("Sending interrupted", e);
}
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
Ten sposób wysyłki gwarantuje największą spójność danych, ale jednocześnie największe opóźnienia, z racji blokowania wątku aplikacji na czas odbioru potwierdzenia z brokera. Synchroniczna wysyłka powinna być używana, kiedy zależy nam na spójności, kolejności danych.
Asynchronous send
Czyli asynchroniczna wysyłka – używamy metody send() z funkcją callback, która trigeruje odpowiedź brokera. Producent nie jest blokowany do czasu uzyskania odpowiedzi z brokera).
Załóżmy, że czas pomiędzy wysłaniem wiadomości a odebraniem odpowiedzi z klastra Kafki to 10ms.
- Wówczas wysłanie 100 wiadomości będzie trwało ok. 1 sekundy.
- Jeśli nie chcemy czekać na synchroniczną odpowiedź klastra Kafki, ale nadal chcemy przechwytywać błędy producenta – dodajmy callback do funkcji wysyłającej
private class DemoProducerCallback implements Callback {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e != null) {
log.error("Error while sending", e);
}
}
}
ProducerRecord<String, String> record =
new ProducerRecord<>("topic", "key", "value");
producer.send(record, new DemoProducerCallback());
Co ważne zaznaczenia – w przypadku asynchronicznej wysyłki, zachowanie kolejności komunikatów niekoniecznie musi być zachowane. Przkładowo – wysyłamy wiadomości #1, #2 oraz #3. Dostarczenie wiadomości #2 nie powiodło się na skutek chwilowych problemów z siecią. Wiadomość #3 została zapisana (bo problemy z siecią już ustąpiły). Producent automatycznie próbuje ponownie wysłać #2, ponieważ błędy sieci zaliczają się do automatycznych ponowień komunikacji (jeśli ustawimy retry config). Wysłanie powiodło się – i teraz mamy taką kolejność wiadomości #1, #3 oraz #2 – kolejność nie została zachowana. W przypadku synchronicznego producenta nie wyślemy kolejnej wiadomości, jeśli nie odbierzemy potwierdzenia z wysłania poprzedniej wiadomości – kolejność danych w tym przypadku jest zachowana.
W podejściu asynchronicznym liczba wiadomości, które są „w locie” jest kontrolowana przez parametr max.in.flight.requests.per.connection.
Apache Kafka – wydajność vs. gwarancja dostarczenia wiadomości
Jak stworzyć piekielnie szybką albo maksymalnie bezpieczną wersję producenta oraz konsumenta.
Podsumowanie
Fire and forget użyjemy, jeśli zależy nam na wysokiej przepustowości, ale nie dbamy o utratę komunikacji. Synchroniczna wysyłka gwarantuje kolejność wysyłki, ale także największą spójność danych z tych trzech metod. Synchroniczna wysyłka blokuje jednak wątek aplikacji, w oczekiwaniu na odpowiedź brokera. Asynchroniczna wysyłka jest czymś pomiędzy – nie gwarantuje kolejności zapisu, ale możemy reagować na błędy zwrócone przez brokera, nie blokując wątku aplikacji.
W tym wpisie poruszyliśmy temat producenta wiadomości w systemie Apache Kafka. W kolejnym wpisie z serii poruszymy temat konsumenta wiadomości – jest tam troszkę więcej do omówienia, dla tego postanowiłem rozbić to na dwa artykuły. Jeśli nie chcesz, aby ominęły Cię artykuły od SoftwareSkill – dołącz od naszego newslettera a pierwszy/a otrzymasz powiadomienie, jeśli pojawi się nowy artykuł 🙂
Wpis który czytasz to zaledwie fragment wiedzy zawartej w Programie szkoleniowym Java Developera od SoftwareSkill. Mamy do przekazania sporo usystematyzowanej wiedzy z zakresu kluczowych kompetencji i umiejętności Java Developera. Program składa się z kilku modułów w cotygodniowych dawkach wiedzy w formie video.
Na koniec mam do Ciebie ogromną prośbę. Dla twórcy bardzo ważni są czytelnicy. Będę bardzo wdzięczny, jeśli podzielisz się niniejszym wpisem w kanałach social media. A jeśli jeszcze nie polubiłeś naszego FanPage na FaceBook – tu jest link https://www.facebook.com/softwareskill
Zakończenie
Kafka w zależności od biznesu oferuje aż 3 typy wysyłania wiadomości: fire and forget, synchronous send oraz asynchronous send
Obowiązkowo musimy ustawić bootstrap.servers, key.serializer, value.serializer
Gdybyś potrzebował jeszcze więcej:
Jesteś Java Developerem?
Przejdź na wyższy poziom wiedzy
„Droga do Seniora” 🔥💪
Jesteś Team Leaderem? Masz zespół?
Podnieś efektywność i wiedzę swojego zespołu 👌
Podoba Ci się ten artykuł? Weź więcej.
Jeżeli uważasz ten materiał za wartościowy i chcesz więcej treści tego typu – nie przegap ich i otrzymuj je prosto na swoją skrzynkę. Nawiążmy kontakt.
Piguła wiedzy o najlepszych praktykach testowania w Java
Pobierz za darmo książkę 100 stron o technikach testowania w Java

