Od pewnego czasu produkcyjnie wykorzystuję Apache Kafka. Zauważyłem, że w aplikacjach, nad którymi pracuję istnieje kilka często powtarzających się błędów.
Muszę Ci się przyznać, że właściwie to uniknęliśmy poważnej produkcyjnej wpadki. Związana była z gwarancją dostarczenia wiadomości, w sytuacji, gdy polegaliśmy na domyślnych ustawieniach. Default, to default, prawda?
To mnie natchnęło, żeby popełnić kolejny wpis. Chciałbym podzielić się swoim doświadczeniem. Zwróć uwagę na to, jakie są domyślne ustawienia parametrów, które opisuję.
Konsument Kafki jest używany do optymalnego odczytywania wiadomości z partycji topika, który subskrybuje. Główną rolą konsumenta jest wziąć połączenie do klastra Kafki oraz ustawienia konsumenta, aby połączyć się z brokerem i zacząć odczytywać wiadomości. Oprócz samego czytania wiadomości konsument w Kafce oferuje nam gwarancje dostarczenia dla konsumenta, commit offsetu, grupy konsumentów, koordynacje konsumentów i wiele innych rzeczy, które wykonywane są „w tle” bez angażowania programisty.
Z tego artykułu dowiesz się
- Jaka jest rola konsumenta wiadomości
- Jakie są obowiązkowe parametry konsuemnta
- Jak napisać konsumenta wiadomości w Java
- Czym jest offset i kiedy jest komitowany
- Jakie są rodzaje komitu offsetu i kiedy je stosujemy
- Jakie są gwarancje dostarczenia dla konsumenta
Apache Kafka – wydajność vs. gwarancja dostarczenia wiadomości
Jak stworzyć piekielnie szybką albo maksymalnie bezpieczną wersję producenta oraz konsumenta.

Ten artykuł jest kontynuacją serii artykułów o Apache Kafka. Aby zrozumieć zagadnienia omawiane w tym wpisie, powinieneś/aś rozumieć czym jest Apache Kafka i w jaki sposób działa – w jednym z poprzednich wpisów z serii opisałem to w bardzo przystępny i szczegółowy sposób.
Zapraszam serdecznie do zapoznania się z poprzednikami tego artykułu:
Parametry konsumenta
Konsument wiadomości w Kafka używa parametrów do określenia swoich ustawień w Klastrze Kafki i tego, jak Klaster ma go traktować (np. wysyłaj mi mniej danych, bo nie wyrabiam z procesowaniem wiadomości). Parametry dzielimy na obowiązkowe i te dodatkowe.
Obowiązkowe ustawienia konsumenta
Obowiązkowe parametry konsumenta to głównie informacje służące do podłączenia się z Klastrem Kafki. Są to:
bootstrap.servers
To lista [host:port] definiująca brokery do inicjalnego połączenia z klastrem Kafki. Nie musi to być pełna lista wszystkich brokerów (w końcu API jest przeźroczyste i konsument nie musi zdawać sobie świadomości ze struktury klastra). Warto jest jednak dać kilka brokerów, jeśli jeden z nich ulegnie awarii, konsument spróbuje połączyć się z kolejnym z listy.
key.deserializer
Nazwa klasy użyta jako deserializer danych. Kafka przyjmuje tablicę bajtów, jednak w kodzie chcielibyśmy operować wygodnymi obiektami. Ten parametr wskazuje na klasę deserializującą dane z postaci binarnej do wygodnej klasy w Java. Klasa deserializatora musi implementować interfejs org.apache.kafka.common.serialization.Deserializer. Można pisać własne deserializatory jednak Kafka oferuje już gotowe np.: StringDeserializer, and IntegerDeserializer.
value.deserializer
Podobnie jak key.deserializer – klasa deserializująca wartość wiadomość do postaci wygodnej w użyciu klasy.
group.id
To ustawienie mówi, do jakiej grupy konsumentów będzie należeć instancja naszego konsumenta (o grupach konsumentów porozmawiamy za chwilkę).
Zobaczmy, jak może wyglądać konfiguracja obowiązkowych parametrów w Java.
Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers","broker1:9092,broker2:9092");
kafkaProps.put("group.id", "grupa-1");
kafkaProps.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
kafkaProps.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
lub czyściej:
static final String GROUP_ID = "group-1";
static final String BOOTSTRAP_SERVERS = "127.0.0.1:9092";
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
Opcjonalne parametry konsumenta
Oprócz tych obowiązkowych ustawień – Apache Kafka oferuje ustawienia, dzięki którym jesteśmy w stanie sterować tym ile danych (wiadomości do prze-procesowania) otrzymamy w jednym responsie, jaki typ commitu offsetu będzie wykorzystywany i wiele innych. Na temat opisu tych parametrów można by napisać niejedną książkę. Poniżej wymienię kilka według mnie najbardziej istotnych:
- enable.auto.commit [default true] – włącza automatyczny commit offsetu odczytanych wiadomości. Kiedy parametr ustawimy na false – sami manualnie musimy zatroszczyć się o commit offsetu. Manualny commit offsetu zalecany jest, jeśli zależy nam na jak największej spójności danych.
- session.timeout.ms – jest dla wątku Kafki wysyłającego request heartbeat. Jeśli koordynator grupy nie otrzyma requestu heartbeat przed upływem tego czasu – oznacza to, że konsument ma problemy, skoro nie może wysłać requestu do Klastra Kafki – żeby poinformować go, że wszystko jest ok. Wówczas koordynator grupy oznacza konsumenta jako nieaktywnego i wymusza proces rebalancingu, aby przypisać jego partycję komuś innemu.
- heartbeat.interval.ms – kontroluje jak często będzie wysyłany request heartbeat do koordynatora grupy. Zaleca się, aby ten czas ustawić na ok. 1/3 wartości parametru session.timeout.ms
Konsument Apache Kafka w Java
Stworzenie konsumenta w Java jest bardzo proste (o ile zadowolimy się domyślnymi ustawieniami, o czym później). Poniżej prezentuje kod w Java, gdzie w pierwszym kroku tworzymy propertisy służące do podłączenia się do Klastra Kafki. Następnie tworzymy instancje KafkaConsumer, aby w końcu za subskrybować się w konkretnym topiku i zacząć czytać wiadomości. Na końcu zamykamy połączenie.
static final String TOPIC_NAME = "softwareskill_safe_topic";
static final String BOOTSTRAP_SERVERS = "localhost:9092";
static final String GROUP_ID = "group-1";
public static void main(String[] args) {
//1. create consumer properties
Properties consumerProps = new Properties();
consumerProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
consumerProps.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
consumerProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
consumerProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 2. Create KafkaConsumer
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(consumerProps);
// 3. Subscribe the topic
consumer.subscribe(Collections.singletonList(TOPIC_NAME));
//4. Poll records
try {
while (true) { // bad practice while(true)
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(10000));
for (ConsumerRecord<String, String> record : records) {
log.info("topic = {}, partition = {}, offset = {}, key = {}, value = {}",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
//doing something with records
}
}
} catch (Exception e) {
log.error("Exception while poll messages", e);
} finally {
// 5. Close the consumer
consumer.close();
}
}
Grupy konsumentów
Może się zdarzyć taka sytuacja, kiedy:
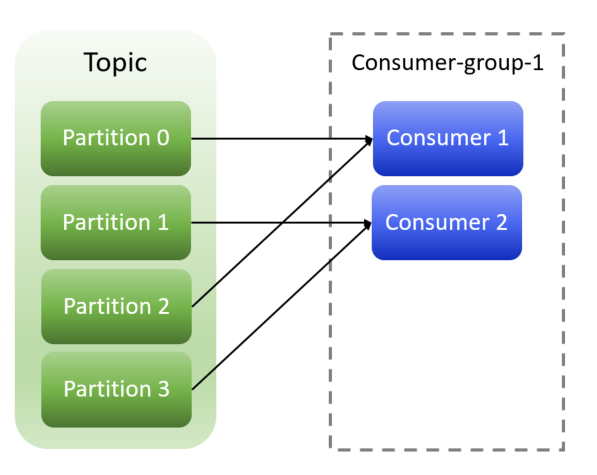
- Chcemy, aby ruch z topiku był rozkładany pomiędzy dwóch konsumentów, tak aby zrównoleglić procesowanie wiadomości i zabezpieczyć konsumentów przed awarią, któregoś z nich. Wówczas będzie nam zależało na tym, aby każdy z konsumentów dostał część wiadomości (żeby odczyt wiadomości nie był powielany). Prezentuje to schemat poniżej, gdzie oba konsumenty znajdują się w tej samej grupie konsumentów (parametr group-id). Konsument 1 czyta inne partycje niż Konsument 2
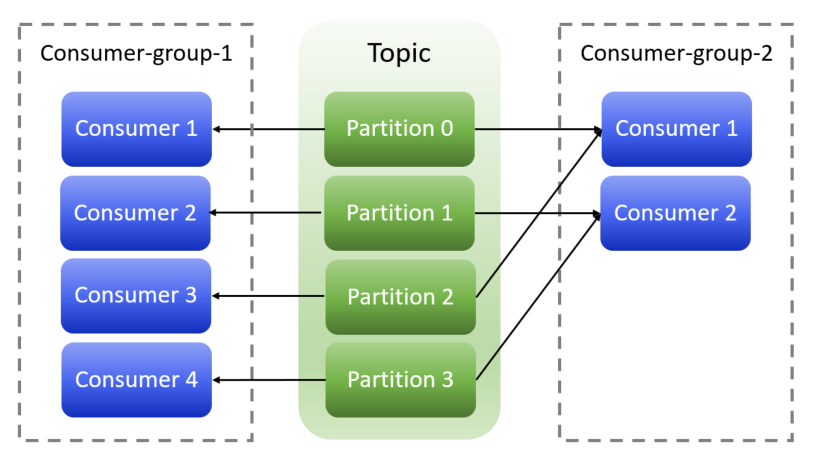
- Inna sytuacja to taka, kiedy chcemy, aby konsumenci odczytywali te same dane (żeby nie podbierali sobie komunikatów). Jako przykład można dodać kolejkowanie zmian danych użytkownika. Kiedy dołącza nowa aplikacja, która chce historię zmian użytkownika – dołącza do kolejki, subskrybuje topic z użytkownikami. Żeby konsument dostał wiadomości od początku (a nie od ostatnio odczytanego offsetu) – musi ustawić swoją grupę, na taką, której jeszcze nie ma. Prezentuje to poniższy slajd, gdzie grupa konsumentów „consumer-group-1” otrzyma takie same komunikaty jak grupa konsumentów „consumer-group-2„.
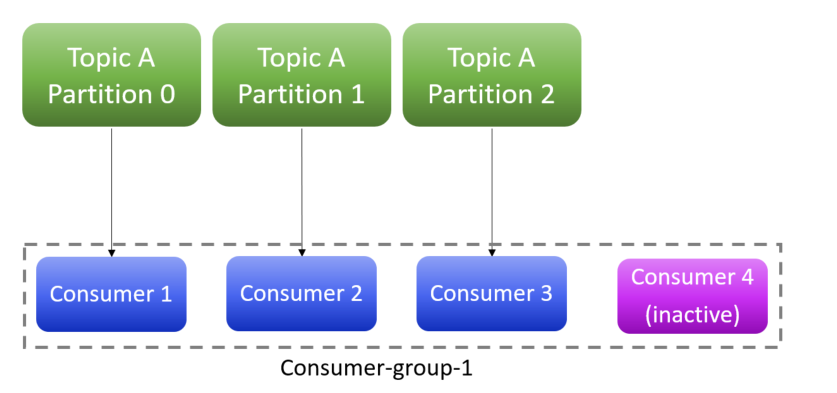
Warto jest dodać, że instancji konsumentów może być maksymalnie tyle, ile jest partycji danego topika. Jeśli instancji konsumentów będzie więcej niż partycji – te nadmiarowe konsumenty będą nieaktywne (taką sytuację prezentuje poniższa fotografia).
Offset wiadomości
Kafka przechowuje na brokerach informację o tym, które wiadomości zostały już przeczytane, a które nie. Dzięki temu w przypadku awarii jednej instancji konsumenta – drugi konsument wie odkąd zacząć czytać daną partycję. Warto jest dodać, że offset dla partycji 1 to nie to samo co offset dla partycji 2. Sam offset można porównać do numeru strony w książce. Przykładowo:
- Czytamy książkę
- Do drzwi dzwoni kurier
- Zapamiętujemy numer strony, gdzie skończyliśmy czytać (zapisujemy offset)
- Kiedy wracamy do czytania książki (partycji) wiemy odkąd zacząć czytać wiadomości – właśnie dzięki zapisanemu offsetowi
Jednak aby Klaster Kafki wiedział, jaki jest ostatnio zapisany nr offsetu dla danej partycji i grupy konsumentów – to konsument musi zakomitować offset. I tutaj dochodzimy do kolejnego zagadnienia – czyli rodzaje commitu offsetu w Apache Kafka.
Apache Kafka – wydajność vs. gwarancja dostarczenia wiadomości
Jak stworzyć piekielnie szybką albo maksymalnie bezpieczną wersję producenta oraz konsumenta.
Rodzaje commitu offsetu
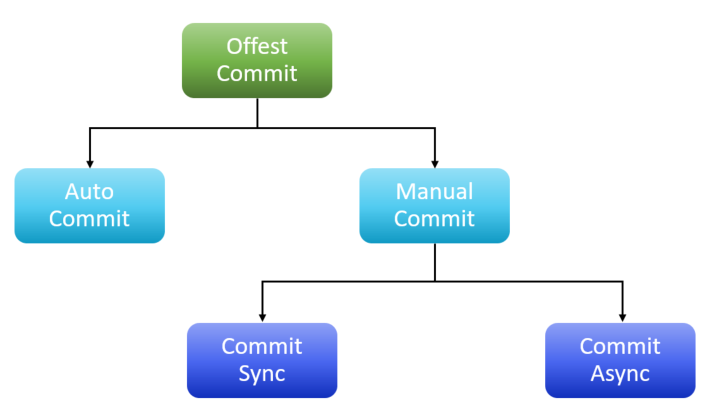
W Kafce rozróżniamy 3 rodzaje commitu offsetu, są to: commit automatyczny, commit manualny synchroniczny, commit manualny asynchroniczny – prezentuje to poniższy slajd:
Autmatyczny commit offsetu
Automatyczny commit to ten najprostrzy – nic nie musimy robić, jest to domyślny tryb Kafka (ustawiony za pomocą parametru enable.auto.commit=true). Tutaj co jakiś zdefiniowany interwał czasowy (auto.commit.interval.ms), przy pobraniu wiadomości, czy przy zamknięciu połączenia wysyłany jest request commitu ostatniej pobranej wiadomości.
Manualny, synchroniczny commit offsetu
Jeśli chcemy mieć większą kontrolę nad tym, kiedy commitować offset (a pozwoli nam to na uniknięcie dubli czy utraty wiadomości, o czym później) powinniśmy użyć manualnego commitu – ponieważ to my decydujemy, kiedy request commitu wysłać (a nie timer czy zasady). Commit synchroniczny jest commitem blokującym a co za tym idzie jest bardzo pewny. Mianowicie – blokujemy wątek aplikacji i nie czytamy dalej partycji, dopóki Kafka nie potwierdzi nam, że żądanie commitu offsetu otrzymała (albo zwróci błąd, jeśli cos pójdzie nie tak).
Manualny, asynchroniczny commit offsetu
To drugi rodzaj manualnego commitu offsetu – nie blokujemy wątku aplikacji i pomimo wysłania żądania commitu – dalej procesujemy odczytywanie wiadomości. Ten rodzaj commitu jest szybki, ale nie daje nam pewności, że Klaster Kafki otrzyma od nas żądanie zakomitowania offsetu.
Gwarancje dostarczenia dla konsumenta
Podobnie jak w przypadku producenta – Apache Kafka oferuje gwarancje dostarczenia dla konsumenta. Od strony producenta wystarczy ustawić parametr „acks” aby powiedzieć Klastrowi, o jaką gwarancję dostarczenia nam chodzi (Kafka musi wiedzieć, czy w ogóle nie odsyłać potwierdzenia dostarczenia dola producenta, czy wysłać, jeśli broker odbierze wiadomość albo może dopiero jak wiadomość fizycznie zostanie zapisana na partycji topika). Od strony konsumenta nie możemy po prostu ustawić jednego parametru, ponieważ tutaj chodzi o moment commitu offsetu wiadomości, o czym za chwilę.

At-most-once
To domyślny tryb (przez domyślnie włączony auto commit). Commit offsetu do Klastra Kafki wysyłany jest od razu po otrzymaniu wiadomości (oraz co jakiś interwał czasowy), Commitowany jest offset ostatniej odczytanej wiadomości. W tym trybie narażamy się na utratę komunikacji. Wyobraźmy sobie sytuację, kiedy otrzymaliśmy jako konsument 100 wiadomości. Od razu po otrzymaniu wiadomości wysyłamy potwierdzenie, że już je przeczytaliśmy (commit ostatniego offsetu), a nawet nie zaczeliśmy procesować wiadomości. Teraz, jeśli konusment ulegnie awarii – nie przeczytamy już tych wiadomości, ponieważ następny zestaw wiadomości będzie się zaczynał od ostatnio zakomitowanego offsetu!
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
At-least-once
To kolejny tryb – commit offsetu jest wysyłany na samym końcu – dopiero po prze-procesowaniu wszystkich wiadomości. To też nie jest idealna sytuacja, ale lepsza niż poprzednia. Mianowicie – co się stanie, jeśli otrzymamy 100 wiadomości, 50 z nich przerobimy a przy procesowaniu 51wszej wiadomości ulegniemy awarii i nie będziemy w stanie wysłać żądania commitu offsetu jako konsument? Wówczas inna instancja (albo my po restarcie) zacznie czytać od ostatnio zakomitowanego offsetu – czyli zacznie czytać wiadomości już przez nas przerobione plus wiadomości, których nie zdążyliśmy przerobić. W konsekwencji w naszym systemie mogą powstać duplikaty wiadomości. Dla tego właśnie nasz konsument powinien być idempotentny (odporny na kilkukrotne wykonanie tego samego żądania). Będzie to lepsza sytuacja niż poprzednia – bo nie zgubimy komunikacji.
Exactly-once
To ostatni tryb, nie jest oferowany wprost w konsumencie Kafki (tylko w Kafka Streams). Oznacza, że wiadomość zostanie odczytana dokładnie jeden raz (nie będzie duplikatów) oraz nie pominiemy żadnej komunikacji.
Wpis który czytasz to zaledwie fragment wiedzy zawartej w Programie szkoleniowym Java Developera od SoftwareSkill. Mamy do przekazania sporo usystematyzowanej wiedzy z zakresu kluczowych kompetencji i umiejętności Java Developera. Program składa się z kilku modułów w cotygodniowych dawkach wiedzy w formie video.
Podumowanie
Kafka oferuje ustawienia pod niemalże każde wyzwanie biznesowe. Jeśli zależy nam na jak najmniejszej ilości ustawień (szybka wersja konsumenta, ale narażona na utratę czy pojawienie się duplikatów wiadomości) – mamy pewny zbiór ustawień (domyślnych). Jeśli chcemy maksymalnie zabezpieczyć naszego konsumenta i sprawić, aby dane były jak najlepszej jakości (minimalizacja utraty i duplikacji wiadomości) – mamy taką możliwość – wystarczy użyć innych ustawień!
Gdybyś potrzebował jeszcze więcej:
Jesteś Java Developerem?
Przejdź na wyższy poziom wiedzy
„Droga do Seniora” 🔥💪
Jesteś Team Leaderem? Masz zespół?
Podnieś efektywność i wiedzę swojego zespołu 👌
Podoba Ci się ten artykuł? Weź więcej.
Jeżeli uważasz ten materiał za wartościowy i chcesz więcej treści tego typu – nie przegap ich i otrzymuj je prosto na swoją skrzynkę. Nawiążmy kontakt.
